
Vrednost povprečne vrednosti je odvisna od posameznika. Povzetek: Povprečne vrednosti, uporabljene v statistiki. Proizvodnja delavcev brigade na izmeno, kos
Najpogostejša vrsta povprečja je aritmetična sredina.
enostavna aritmetična sredina
Preprosta aritmetična sredina je povprečni izraz, pri določanju katerega je skupni obseg danega atributa v podatkih enakomerno porazdeljen med vse enote, vključene v to populacijo. Tako je povprečna letna proizvodnja na delavca taka vrednost obsega proizvodnje, ki bi padla na vsakega zaposlenega, če bi bil celoten obseg proizvodnje enakomerno porazdeljen med vse zaposlene v organizaciji. Aritmetična sredina enostavne vrednosti se izračuna po formuli:
enostavna aritmetična sredina— Enako razmerju med vsoto posameznih vrednosti lastnosti in številom lastnosti v agregatu
Primer 1. Ekipa 6 delavcev prejme 3 3,2 3,3 3,5 3,8 3,1 tisoč rubljev na mesec.
Poiščite povprečno plačo
Rešitev: (3 + 3,2 + 3,3 +3,5 + 3,8 + 3,1) / 6 = 3,32 tisoč rubljev.
Aritmetično tehtano povprečje
Če je obseg nabora podatkov velik in predstavlja niz porazdelitve, se izračuna tehtana aritmetična sredina. Tako se določi tehtana povprečna cena na enoto proizvodnje: celotni proizvodni strošek (vsota zmnožkov njegove količine in cene enote proizvodnje) se deli s skupno količino proizvodnje.
To predstavimo v obliki naslednje formule:
![]()
Utežena aritmetična sredina- je enak razmerju (vsota zmnožkov vrednosti atributa na pogostost ponavljanja tega atributa) proti (vsota frekvenc vseh atributov).Uporablja se, kadar se različice proučevane populacije pojavljajo neenako številokrat.
Primer 2. Poiščite povprečne mesečne plače delavcev v trgovini
Povprečno plačo lahko dobimo tako, da celotno plačo delimo s skupnim številom delavcev:

Odgovor: 3,35 tisoč rubljev.
Aritmetična sredina za intervalno serijo
Pri izračunu aritmetične sredine za intervalno variacijsko serijo se najprej določi povprečje za vsak interval kot polovična vsota zgornje in spodnje meje, nato pa povprečje celotne serije. Pri odprtih intervalih je vrednost spodnjega ali zgornjega intervala določena z vrednostjo intervalov, ki so ob njih.
Povprečja, izračunana iz intervalnih vrst, so približna.
Primer 3. Ugotovite povprečno starost učencev večernega oddelka.

Povprečja, izračunana iz intervalnih vrst, so približna. Stopnja njihovega približevanja je odvisna od tega, v kolikšni meri se dejanska porazdelitev populacijskih enot znotraj intervala približuje enakomerni.
Pri izračunu povprečij se lahko kot uteži uporabljajo ne samo absolutne, ampak tudi relativne vrednosti (frekvenca):
Aritmetična sredina ima številne lastnosti, ki bolj razkrivajo njeno bistvo in poenostavljajo izračun:
1. Zmnožek povprečja in vsote frekvenc je vedno enak vsoti zmnožkov variant in frekvenc, tj.
![]()
2. Aritmetična sredina vsote spremenljivih vrednosti je enaka vsoti aritmetičnih sredin teh vrednosti:
3. Algebraična vsota odstopanj posameznih vrednosti atributa od povprečja je nič.
Povprečna vrednost- to je generalizacijski indikator, ki označuje kvalitativno homogeno populacijo glede na določeno kvantitativno lastnost. Na primer povprečna starost oseb, obsojenih za tatvino.
V sodni statistiki se povprečja uporabljajo za opredelitev:
Povprečni roki obravnave primerov te kategorije;
Zahtevek srednje velikosti;
Povprečno število obtožencev na zadevo;
Povprečna višina škode;
Povprečna obremenitev sodnikov itd.
Povprečna vrednost je vedno imenovana in ima enako dimenzijo kot atribut posamezne enote populacije. Vsaka povprečna vrednost označuje proučevano populacijo po katerem koli spremenljivem atributu, zato za vsakim povprečjem obstaja niz porazdelitev enot te populacije glede na proučevani atribut. Izbira vrste povprečja je odvisna od vsebine kazalnika in izhodiščnih podatkov za izračun povprečja.
Vse vrste povprečij, ki se uporabljajo v statističnih študijah, spadajo v dve kategoriji:
1) povprečja moči;
2) strukturna povprečja.
Prva kategorija povprečij vključuje: aritmetična sredina, harmonična sredina, geometrična sredina in efektivna vrednost . Druga kategorija je moda in mediana. Poleg tega ima lahko vsaka od naštetih vrst povprečij moči dve obliki: preprosto in tehtano . preprosta oblika povprečna vrednost se uporablja za pridobitev povprečne vrednosti proučevane lastnosti, kadar se izračun izvaja na nezdruženih statističnih podatkih ali kadar se vsaka različica v populaciji pojavi samo enkrat. Utežena povprečja so vrednosti, ki upoštevajo, da imajo možnosti za vrednosti lastnosti lahko različna števila, zato je treba vsako možnost pomnožiti z ustrezno frekvenco. Z drugimi besedami, vsaka možnost je "pretehtana" glede na svojo pogostost. Pogostost se imenuje statistična utež.
enostavna aritmetična sredina- najpogostejša vrsta medija. Enak je vsoti posameznih značilnih vrednosti, deljenih s skupnim številom teh vrednosti:
kje x 1 ,x 2 , … ,x N- posamezne vrednosti atributa spremenljivke (možnosti) in N - število populacijskih enot.
Aritmetično tehtano povprečje uporablja se, ko so podatki predstavljeni v obliki porazdelitvenih serij ali skupin. Izračuna se kot vsota zmnožkov možnosti in njihovih ustreznih frekvenc, deljena z vsoto frekvenc vseh možnosti:
kje x i- pomen jaz-th različice značilnosti; fi- pogostost jaz th možnosti.
Tako je vsaka vrednost variant ponderirana s svojo frekvenco, zato se frekvence včasih imenujejo statistične uteži.
Komentiraj. Ko gre za aritmetično sredino brez navedbe njene vrste, je mišljena preprosta aritmetična sredina.
Tabela 12
rešitev. Za izračun uporabimo formulo aritmetičnega tehtanega povprečja:
Tako sta v povprečju dva obtoženca na eno kazensko zadevo.
Če se izračun povprečne vrednosti izvede glede na podatke, združene v obliki nizov intervalne porazdelitve, morate najprej določiti mediane vrednosti vsakega intervala x "i in nato izračunati povprečno vrednost z uporabo formula utežene aritmetične sredine, v kateri je x" i nadomeščen z x i.
Primer. Podatki o starosti obsojenih storilcev tatvin so predstavljeni v tabeli:
Tabela 13
Določite povprečno starost kriminalcev, obsojenih za tatvino.
rešitev.Če želite določiti povprečno starost kriminalcev na podlagi serije variacij intervalov, morate najprej najti mediane vrednosti intervalov. Ker je podana serija intervalov z odprtimi prvimi in zadnjimi intervali, so vrednosti teh intervalov enake vrednostim sosednjih zaprtih intervalov. V našem primeru sta vrednost prvega in zadnjega intervala 10.
Zdaj najdemo povprečno starost kriminalcev z uporabo formule utežene aritmetične sredine:
Tako je povprečna starost obsojenih storilcev tatvin približno 27 let.
Povprečno harmonično preprosto je recipročna vrednost aritmetične sredine vzajemnih vrednosti atributa:
kjer je 1/ x i so recipročne vrednosti možnosti, N pa je število populacijskih enot.
Primer. Za določitev povprečne letne obremenitve sodnikov okrožnega sodišča pri obravnavanju kazenskih zadev je bila opravljena anketa o obremenitvi 5 sodnikov tega sodišča. Izkazalo se je, da je povprečni čas, porabljen za eno kazensko zadevo za vsakega od anketiranih sodnikov, enak (v dnevih): 6, 0, 5, 6, 6, 3, 4, 9, 5, 4. Poiščite povprečne stroške za enega kazenski zadevi in povprečna letna obremenitev sodnikov tega okrožnega sodišča pri obravnavanju kazenskih zadev.
rešitev. Za določitev povprečnega časa, porabljenega za eno kazensko zadevo, uporabimo harmonično preprosto formulo:
Za poenostavitev izračunov v primeru vzemimo število dni v letu 365, vključno z vikendi (to ne vpliva na metodo izračuna in pri izračunu podobnega kazalnika v praksi je treba nadomestiti število delovnih dni v posameznem letu namesto 365 dni). Potem bo povprečna letna obremenitev sodnikov tega okrožnega sodišča pri obravnavanju kazenskih zadev: 365 (dni): 5,56 ≈ 65,6 (zadeve).
Če bi uporabili preprosto formulo aritmetične sredine za določitev povprečnega časa, porabljenega za eno kazensko zadevo, bi dobili:
365 (dnevi): 5,64 ≈ 64,7 (primeri), tj. povprečna obremenitev sodnikov je bila manjša.
Preverimo veljavnost tega pristopa. Za to uporabimo podatke o času, porabljenem za eno kazensko zadevo za vsakega sodnika, in izračunamo število kazenskih zadev, ki jih obravnava vsak od njih na leto.
Temu primerno dobimo:
365(dni) : 6 ≈ 61 (primer), 365(dni) : 5,6 ≈ 65,2 (primer), 365(dni) : 6,3 ≈ 58 (primer),
365(dni) : 4,9 ≈ 74,5 (primeri), 365(dni) : 5,4 ≈ 68 (primeri).
Zdaj izračunamo povprečno letno obremenitev sodnikov tega okrožnega sodišča pri obravnavanju kazenskih zadev:
Tisti. povprečna letna obremenitev je enaka kot pri uporabi harmonične sredine.
Tako je uporaba aritmetične sredine v tem primeru nezakonita.
V primerih, ko so različice značilnosti znane, njihove volumetrične vrednosti (zmnožek različic s frekvenco), vendar same frekvence niso znane, se uporabi harmonična tehtana povprečna formula:
kje x i so vrednosti možnosti lastnosti in w i so volumetrične vrednosti možnosti ( w i = x i f i).
Primer. Podatki o ceni enote istovrstnega blaga, ki ga proizvajajo različne ustanove kazenskega sistema, in o obsegu njegove realizacije so podani v tabeli 14.
Tabela 14
Poiščite povprečno prodajno ceno izdelka.
rešitev. Pri izračunu povprečne cene moramo uporabiti razmerje med prodano količino in številom prodanih enot. Ne poznamo števila prodanih enot, poznamo pa količino prodaje blaga. Zato za iskanje povprečne cene prodanega blaga uporabimo formulo za harmonično tehtano povprečje. Dobimo
Če tukaj uporabite formulo aritmetične sredine, lahko dobite povprečno ceno, ki bo nerealna:
Geometrijska sredina se izračuna tako, da se iz zmnožka vseh vrednosti možnosti lastnosti izvleče koren stopnje N:
kje x 1 ,x 2 , … ,x N- posamezne vrednosti spremenljive lastnosti (možnosti) in
n- število populacijskih enot.
Ta vrsta povprečja se uporablja za izračun povprečnih stopenj rasti časovnih vrst.
efektivna vrednost se uporablja za izračun standardnega odklona, ki je indikator variacije in bo obravnavan v nadaljevanju.
Za ugotavljanje strukture prebivalstva se uporabljajo posebna povprečja, ki vključujejo mediana in moda , ali tako imenovana strukturna povprečja. Če je aritmetična sredina izračunana na podlagi uporabe vseh variant vrednosti atributa, potem mediana in moda označujeta vrednost variante, ki zavzema določeno povprečno mesto v rangirani (urejeni) seriji. Urejanje enot statistične populacije se lahko izvede v naraščajočem ali padajočem vrstnem redu glede na različice proučevane lastnosti.
Mediana (jaz) je vrednost, ki ustreza različici na sredini razvrščene serije. Mediana je torej tista različica rangirane serije, na obeh straneh katere mora biti v tej seriji enako število populacijskih enot.
Če želite najti mediano, morate najprej določiti njeno zaporedno številko v rangirani seriji z uporabo formule:
kjer je N obseg serije (število populacijskih enot).
Če je serija sestavljena iz lihega števila članov, potem je mediana enaka varianti s številom N Me . Če je serija sestavljena iz sodega števila članov, potem je mediana definirana kot aritmetična sredina dveh sosednjih možnosti, ki se nahajata na sredini.
Primer. Podana je razvrščena serija 1, 2, 3, 3, 6, 7, 9, 9, 10. Prostornina serije je N = 9, kar pomeni N Me = (9 + 1) / 2 = 5. Zato je Me = 6, tj. peta možnost. Če je vrstica podana s številkami 1, 5, 7, 9, 11, 14, 15, 16, tj. serije s sodim številom članov (N = 8), potem je N Me = (8 + 1) / 2 = 4,5. Torej je mediana enaka polovici vsote četrte in pete možnosti, tj. Jaz = (9 + 11) / 2 = 10.
V seriji diskretnih variacij je mediana določena z akumuliranimi frekvencami. Različne frekvence, začenši s prvo, se seštevajo, dokler ni presežena mediana. Vrednost zadnjih seštetih opcij bo mediana.
Primer. Poiščite mediano število obtožencev na kazensko zadevo s pomočjo podatkov v tabeli 12.
rešitev. V tem primeru je prostornina variacijske serije N = 154, zato je N Me = (154 + 1) / 2 = 77,5. Če seštejemo frekvence prve in druge možnosti, dobimo: 75 + 43 = 118, tj. smo presegli mediano število. Torej jaz = 2.
V nizu intervalnih variacij porazdelitve najprej označite interval, v katerem bo mediana. Imenuje se mediana . To je prvi interval, katerega kumulativna frekvenca presega polovico volumna variacijske serije intervala. Potem je številčna vrednost mediane določena s formulo:
kje x Jaz- spodnja meja medianega intervala; i - vrednost medianega intervala; S Me-1- akumulirana frekvenca intervala, ki je pred mediano; f jaz- frekvenca medianega intervala.
Primer. Poiščite povprečno starost storilcev kaznivih dejanj, obsojenih za tatvino, na podlagi statističnih podatkov, predstavljenih v tabeli 13.
rešitev. Statistični podatki so predstavljeni z intervalno variacijsko serijo, kar pomeni, da najprej določimo mediani interval. Obseg populacije N = 162, torej je mediani interval interval 18-28, ker to je prvi interval, katerega akumulirana frekvenca (15 + 90 = 105) presega polovico volumna (162: 2 = 81) intervalne variacijske serije. Zdaj je številčna vrednost mediane določena z zgornjo formulo:
Tako je polovica obsojenih za tatvino mlajših od 25 let.
Moda (Mo) poimenovati vrednost atributa, ki se največkrat nahaja v enotah populacije. Moda se uporablja za identifikacijo vrednosti lastnosti, ki je najbolj razširjena. Za diskretno serijo bo način varianta z najvišjo frekvenco. Na primer za diskretno serijo, predstavljeno v tabeli 3 Mo= 1, saj ta vrednost možnosti ustreza najvišji frekvenci - 75. Za določitev načina intervalne serije najprej določite modalno interval (interval z najvišjo frekvenco). Nato se znotraj tega intervala najde vrednost lastnosti, ki je lahko način.
Njegovo vrednost najdemo po formuli:
kje x Mo- spodnja meja modalnega intervala; i - vrednost modalnega intervala; f Mo- modalna intervalna frekvenca; f Mo-1- pogostost intervala pred modalnim; f Mo+1- pogostost intervala, ki sledi modalu.
Primer. Poiščite starostno obliko storilcev kaznivih dejanj, obsojenih za tatvino, podatki o katerih so predstavljeni v tabeli 13.
rešitev. Najvišja frekvenca ustreza intervalu 18-28, zato mora biti način v tem intervalu. Njegova vrednost je določena z zgornjo formulo:
Tako je največ obsojenih kaznivih dejanj tatvin starih 24 let.
Povprečna vrednost daje splošno značilnost celotnega pojava, ki se proučuje. Vendar pa se lahko dve populaciji z enakimi povprečnimi vrednostmi med seboj bistveno razlikujeta glede na stopnjo nihanja (variacije) vrednosti proučevane lastnosti. Na primer, na enem sodišču so bile dodeljene naslednje kazni zapora: 3, 3, 3, 4, 5, 5, 5, 12, 12, 15 let, na drugem pa 5, 5, 6, 6, 7, 7 let. , 7 , 8, 8, 8 let. V obeh primerih je aritmetična sredina 6,7 leta. Ti agregati pa se med seboj bistveno razlikujejo v razponu posameznih vrednosti pripisane kazni zapora glede na povprečno vrednost.
In za prvo sodišče, kjer je ta razlika precej velika, povprečna doba zapora ne odraža dobro celotne populacije. Torej, če se posamezne vrednosti atributa med seboj malo razlikujejo, bo aritmetična sredina dokaj indikativna značilnost lastnosti te populacije. V nasprotnem primeru bo aritmetična sredina nezanesljiva značilnost te populacije in njena uporaba v praksi neučinkovita. Zato je treba upoštevati variacijo vrednosti proučevane lastnosti.
Različica- to so razlike v vrednostih značilnosti v različnih enotah dane populacije v istem obdobju ali časovni točki. Izraz "variacija" je latinskega izvora - variatio, kar pomeni razlika, sprememba, nihanje. Nastane kot posledica dejstva, da se posamezne vrednosti atributa oblikujejo pod skupnim vplivom različnih dejavnikov (pogojev), ki se v vsakem posameznem primeru kombinirajo na različne načine. Za merjenje variacije lastnosti se uporabljajo različni absolutni in relativni kazalci.
Glavni kazalniki variacije vključujejo naslednje:
1) obseg variacije;
2) povprečno linearno odstopanje;
3) disperzija;
4) standardni odklon;
5) koeficient variacije.
Na kratko se posvetimo vsakemu od njih.
Variacija razpona R je najbolj dostopen absolutni indikator v smislu enostavnosti izračuna, ki je opredeljen kot razlika med največjo in najmanjšo vrednostjo atributa za enote te populacije:
Razpon variacije (razpon nihanj) je pomemben pokazatelj variabilnosti lastnosti, vendar omogoča opazovanje le ekstremnih odstopanj, kar omejuje njegov obseg. Za natančnejšo karakterizacijo variacije lastnosti na podlagi njenega nihanja se uporabljajo drugi indikatorji.
Povprečno linearno odstopanje predstavlja aritmetično sredino absolutnih vrednosti odstopanj posameznih vrednosti lastnosti od sredine in je določena s formulami:
1) za nezdruženih podatkov
2) za variacijske serije
Vendar je najpogosteje uporabljena mera variacije disperzija . Označuje mero širjenja vrednosti preučevane lastnosti glede na njeno povprečno vrednost. Varianca je opredeljena kot povprečje odstopanj na kvadrat.
enostavna varianta za nezdružene podatke:
Utežena varianca za variacijsko serijo:
Komentiraj. V praksi je za izračun variance bolje uporabiti naslednje formule:
Za enostavno varianto
Za tehtano varianco
Standardni odklon je kvadratni koren variance:
Standardni odklon je merilo zanesljivosti povprečja. Manjši kot je standardni odklon, bolj homogena je populacija in bolje aritmetična sredina odraža celotno populacijo.
Zgoraj obravnavane disperzijske mere (razpon variacije, variance, standardni odklon) so absolutni kazalci, po katerih ni vedno mogoče presoditi stopnje nihanja lastnosti. Pri nekaterih problemih je treba uporabiti relativne indekse sipanja, eden izmed njih je koeficient variacije.
Koeficient variacije- izraženo kot odstotek razmerja med standardnim odklonom in aritmetično sredino:
Koeficient variacije se uporablja ne le za primerjalno oceno variacije različnih lastnosti ali iste lastnosti v različnih populacijah, temveč tudi za karakterizacijo homogenosti populacije. Statistična populacija se šteje za kvantitativno homogeno, če koeficient variacije ne presega 33 % (za porazdelitve, ki so blizu normalne porazdelitve).
Primer. Podatki o trajanju zapora 50 obsojencev, ki so bili oddani na prestajanje kazni, ki jih je izreklo sodišče, v prevzgojni zavod sistema za prestajanje kazni zapora so naslednji: 5, 4, 2, 1, 6, 3, 4, 3, 2, 2 , 5, 6, 4, 3 , 10, 5, 4, 1, 2, 3, 3, 4, 1, 6, 5, 3, 4, 3, 5, 12, 4, 3, 2, 4, 6 , 4, 4, 3, 1 , 5, 4, 3, 12, 6, 7, 3, 4, 5, 5, 3.
1. Konstruirajte porazdelitveno serijo glede na zaporne kazni.
2. Poiščite povprečje, varianco in standardni odklon.
3. Izračunajte koeficient variacije in sklepajte o homogenosti ali heterogenosti proučevane populacije.
rešitev. Za sestavo diskretne porazdelitvene serije je treba določiti različice in frekvence. Varianta v tem problemu je trajanje zapora, pogostost pa število posamezne variante. Po izračunu frekvenc dobimo naslednjo diskretno porazdelitveno serijo:
Poiščite povprečje in varianco. Ker so statistični podatki predstavljeni z diskretnimi variacijskimi vrstami, bomo za njihov izračun uporabili formule aritmetičnega tehtanega povprečja in variance. Dobimo:
Zdaj izračunamo standardni odklon:
Najdemo koeficient variacije:
Posledično je statistična populacija kvantitativno heterogena.
V večini primerov so podatki skoncentrirani okoli neke osrednje točke. Tako je za opis katerega koli niza podatkov dovolj navesti povprečno vrednost. Zaporedoma razmislimo o treh numeričnih karakteristikah, ki se uporabljajo za oceno srednje vrednosti porazdelitve: aritmetična sredina, mediana in način.
Povprečje
Aritmetična sredina (pogosto imenovana preprosto povprečje) je najpogostejša ocena srednje vrednosti porazdelitve. Je rezultat deljenja vsote vseh opazovanih številskih vrednosti z njihovim številom. Za vzorec številk X 1, X 2, ..., Xn, povprečje vzorca (označeno s simbolom ) je enako \u003d (X 1 + X 2 + ... + Xn) / n, oz
kje je povprečje vzorca, n- Velikost vzorca, Xjaz – i-ti element vzorcev.
Prenesite opombo v ali formatu, primere v formatu
Razmislite o izračunu aritmetične sredine petletnih povprečnih letnih donosov 15 vzajemnih skladov z zelo visoka stopnja tveganje (slika 1).

riž. 1. Povprečna letna donosnost 15 zelo tveganih vzajemnih skladov
Vzorčno povprečje se izračuna na naslednji način:

To je dober donos, zlasti v primerjavi s 3-4-odstotnim donosom, ki so ga prejeli vlagatelji bank ali kreditnih zadrug v istem časovnem obdobju. Če razvrstite vrednosti donosa, je enostavno videti, da ima osem skladov donos nad, sedem pa pod povprečjem. Aritmetična sredina deluje kot točka ravnotežja, tako da skladi z nizkimi dohodki izravnajo sklade z visokimi dohodki. Pri izračunu povprečja so vključeni vsi elementi vzorca. Nobeden od drugih ocenjevalcev povprečja porazdelitve nima te lastnosti.
Kdaj izračunati aritmetično sredino. Ker je aritmetična sredina odvisna od vseh elementov vzorca, prisotnost ekstremnih vrednosti pomembno vpliva na rezultat. V takšnih situacijah lahko aritmetična sredina popači pomen numeričnih podatkov. Zato je treba pri opisu niza podatkov, ki vsebuje ekstremne vrednosti, navesti mediano ali aritmetično sredino in mediano. Če na primer iz vzorca izločimo donos sklada RS Emerging Growth, se vzorčno povprečje donosa 14 skladov zmanjša za skoraj 1 % na 5,19 %.
Mediana
Mediana je srednja vrednost urejenega niza števil. Če niz ne vsebuje ponavljajočih se števil, bo polovica njegovih elementov manjša od in polovica večja od mediane. Če vzorec vsebuje ekstremne vrednosti, je za oceno sredine bolje uporabiti mediano kot aritmetično sredino. Za izračun mediane vzorca ga je treba najprej razvrstiti.
Ta formula je dvoumna. Njegov rezultat je odvisen od tega, ali je število sodo ali liho. n:
- Če vzorec vsebuje liho število postavk, je mediana enaka (n+1)/2-ti element.
- Če vzorec vsebuje sodo število elementov, leži mediana med srednjima elementoma vzorca in je enaka aritmetični sredini, izračunani nad tema dvema elementoma.
Za izračun mediane za vzorec 15 vzajemnih skladov z zelo visokim tveganjem moramo najprej razvrstiti neobdelane podatke (slika 2). Potem bo mediana nasprotna številki srednjega elementa vzorca; v našem primeru številka 8. Excel ima posebno funkcijo =MEDIAN(), ki deluje tudi z neurejenimi nizi.

riž. 2. Mediana 15 sredstev
Tako je mediana 6,5. To pomeni, da polovica zelo tveganih skladov ne presega 6,5, druga polovica pa to presega. Upoštevajte, da je mediana 6,5 nekoliko večja od mediane 6,08.
Če iz vzorca izločimo donosnost sklada RS Emerging Growth, se bo mediana preostalih 14 skladov znižala na 6,2 %, torej ne tako pomembno kot aritmetična sredina (slika 3).

riž. 3. Mediana 14 sredstev
Moda
Izraz je prvi uvedel Pearson leta 1894. Moda je število, ki se najpogosteje pojavlja v vzorcu (najbolj modno). Moda dobro opiše na primer tipično reakcijo voznikov na prometni signal za ustavitev prometa. Klasičen primer uporabe mode je izbira velikosti proizvedene serije čevljev ali barve ozadja. Če ima porazdelitev več načinov, potem rečemo, da je večmodalna ali multimodalna (ima dva ali več "vrhov"). Multimodalna porazdelitev zagotavlja pomembne informacije o naravi proučevane spremenljivke. Na primer, v socioloških raziskavah, če spremenljivka predstavlja preferenco ali odnos do nečesa, potem lahko multimodalnost pomeni, da obstaja več izrazito različnih mnenj. Multimodalnost je tudi pokazatelj, da vzorec ni homogen in da so lahko opazovanja ustvarjena z dvema ali več "prekrivajočimi se" porazdelitvami. Za razliko od aritmetične sredine izstopajoči ne vplivajo na način. Za zvezno porazdeljene naključne spremenljivke, kot so povprečni letni donosi vzajemnih skladov, način včasih sploh ne obstaja (ali nima smisla). Ker lahko ti kazalniki prevzamejo različne vrednosti, so ponavljajoče se vrednosti izjemno redke.
Kvartili
Kvartili so mere, ki se najpogosteje uporabljajo za vrednotenje porazdelitve podatkov pri opisovanju lastnosti velikih numeričnih vzorcev. Medtem ko mediana razdeli urejeno matriko na pol (50 % elementov matrike je manjših od mediane in 50 % večjih), kvartili razdelijo urejeni niz podatkov na štiri dele. Vrednosti Q 1, mediana in Q 3 so 25., 50. oziroma 75. percentil. Prvi kvartil Q 1 je število, ki vzorec razdeli na dva dela: 25 % elementov je manj kot in 75 % več kot prvi kvartil.
Tretji kvartil Q 3 je število, ki prav tako deli vzorec na dva dela: 75 % elementov je manj kot in 25 % več od tretjega kvartila.
Za izračun kvartilov v različicah Excela pred letom 2007 je bila uporabljena funkcija =QUARTILE(matrika, del). Od Excela 2010 veljata dve funkciji:
- =QUARTILE.ON(niz, del)
- =QUARTILE.EXC(matrika, del)
Ti dve funkciji dajeta nekoliko različne vrednosti (slika 4). Na primer, pri izračunu kvartilov vzorca, ki vsebuje podatke o povprečni letni donosnosti 15 vzajemnih skladov z zelo visokim tveganjem, je Q 1 = 1,8 oziroma -0,7 za QUARTILE.INC oziroma QUARTILE.EXC. Mimogrede, prej uporabljena funkcija QUARTILE ustreza sodobni funkciji QUARTILE.ON. Če želite izračunati kvartile v Excelu z uporabo zgornjih formul, lahko matriko podatkov pustite neurejeno.

riž. 4. Izračunajte kvartile v Excelu
Še enkrat poudarimo. Excel lahko izračuna kvartile za univariate diskretne serije, ki vsebuje vrednosti naključne spremenljivke. Izračun kvartilov za porazdelitev na podlagi frekvence je podan v spodnjem razdelku.
geometrična sredina
Za razliko od aritmetične sredine geometrična sredina meri, koliko se je spremenljivka spremenila skozi čas. Geometrijska sredina je koren n stopnje iz izdelka n vrednosti (v Excelu se uporablja funkcija = CUGEOM):
G= (X 1 * X 2 * ... * X n) 1/n
Podoben parameter - geometrična sredina stopnje donosa - se določi s formulo:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
kje R i- stopnja donosa jaz-to časovno obdobje.
Recimo, da je začetna naložba 100.000 $. Do konca prvega leta pade na 50.000 $, do konca drugega leta pa se povrne na prvotnih 100.000 $. Stopnja donosa te naložbe v dveh letih. letno obdobje je enako 0, saj sta začetni in končni znesek sredstev enaka. Vendar pa je aritmetično povprečje letnih stopenj donosa = (-0,5 + 1) / 2 = 0,25 ali 25 %, saj je stopnja donosa v prvem letu R 1 = (50.000 - 100.000) / 100.000 = -0,5 in v drugem R 2 = (100.000 - 50.000) / 50.000 = 1. Hkrati je geometrična sredina stopnje donosa za dve leti: G = [(1–0,5) * (1 + 1 )] 1 /2 – 1 = ½ – 1 = 1 – 1 = 0. Tako geometrična sredina natančneje odraža spremembo (natančneje odsotnost spremembe) obsega investicij v dvoletnem obdobju kot aritmetična sredina.
Zanimiva dejstva. Prvič, geometrična sredina bo vedno manjša od aritmetične sredine istih števil. Razen v primeru, ko so vsa vzeta števila med seboj enaka. Drugič, ob upoštevanju lastnosti pravokotnega trikotnika lahko razumemo, zakaj se povprečje imenuje geometrijsko. Višina pravokotnega trikotnika, spuščena na hipotenuzo, je povprečni sorazmernik med projekcijama krakov na hipotenuzo, vsak krak pa je povprečni sorazmernik med hipotenuzo in njeno projekcijo na hipotenuzo (slika 5). To daje geometrijski način konstruiranja geometrične sredine dveh segmentov (dolžin): na vsoti teh dveh segmentov morate sestaviti krog kot premer, nato pa višino, obnovljeno od točke njune povezave do presečišča z krog, bo dal želeno vrednost:

riž. 5. Geometrična narava geometrijske sredine (slika iz Wikipedije)
Druga pomembna lastnost numeričnih podatkov je njihova variacija ki označujejo stopnjo razpršenosti podatkov. Dva različna vzorca se lahko razlikujeta tako v srednjih vrednostih kot v variacijah. Vendar, kot je prikazano na sl. 6 in 7 imata lahko dva vzorca enako variacijo, vendar različna povprečja, ali isto povprečje in popolnoma različno variacijo. Podatki, ki ustrezajo poligonu B na sl. 7 spremenijo veliko manj kot podatki, iz katerih je bil zgrajen poligon A.

riž. 6. Dve simetrični zvonasti porazdelitvi z enakim razmazom in različnimi srednjimi vrednostmi

riž. 7. Dve simetrični zvonasti porazdelitvi z enakimi srednjimi vrednostmi in različnim raztrosom
Obstaja pet ocen variacije podatkov:
- razpon,
- interkvartilni razpon,
- disperzija,
- standardni odklon,
- koeficient variacije.
Obseg
Razpon je razlika med največjim in najmanjši elementi vzorci:
Povlecite = XMax-XMin
Razpon vzorca, ki vsebuje povprečne letne donose 15 vzajemnih skladov z zelo visokim tveganjem, je mogoče izračunati z uporabo urejenega niza (glej sliko 4): razpon = 18,5 - (-6,1) = 24,6. To pomeni, da je razlika med najvišjimi in najnižjimi povprečnimi letnimi donosi pri zelo tveganih skladih 24,6 %.
Obseg meri celotno širjenje podatkov. Čeprav je obseg vzorca zelo preprosta ocena celotnega širjenja podatkov, je njegova slabost, da ne upošteva natančno, kako so podatki porazdeljeni med minimalne in maksimalne elemente. Ta učinek je dobro viden na sl. 8, ki prikazuje vzorce z enakim obsegom. Lestvica B kaže, da če vzorec vsebuje vsaj eno ekstremno vrednost, je obseg vzorca zelo netočna ocena razpršenosti podatkov.

riž. 8. Primerjava treh vzorcev z enakim razponom; trikotnik simbolizira podporo ravnotežja, njegova lokacija pa ustreza povprečni vrednosti vzorca
Interkvartilni razpon
Interkvartil ali srednji razpon je razlika med tretjim in prvim kvartilom vzorca:
Interkvartilni razpon \u003d Q 3 - Q 1
Ta vrednost omogoča oceno širjenja 50% elementov in neupoštevanje vpliva ekstremnih elementov. Interkvartilni razpon za vzorec, ki vsebuje podatke o povprečnih letnih donosih 15 vzajemnih skladov z zelo visokim tveganjem, je mogoče izračunati z uporabo podatkov na sliki 1. 4 (na primer za funkcijo QUARTILE.EXC): interkvartilni razpon = 9,8 - (-0,7) = 10,5. Interval med 9,8 in -0,7 se pogosto imenuje srednja polovica.
Upoštevati je treba, da vrednosti Q 1 in Q 3 ter s tem interkvartilni razpon niso odvisni od prisotnosti izstopajočih vrednosti, saj njihov izračun ne upošteva nobene vrednosti, ki bi bila nižja od Q 1 ali večja od Q 3 . Skupne kvantitativne značilnosti, kot so mediana, prvi in tretji kvartil ter interkvartilni razpon, na katere izstopajoči podatki ne vplivajo, se imenujejo robustni indikatorji.
Medtem ko razpon in interkvartilni razpon zagotavljata oceno celotnega oziroma povprečnega razpršenosti vzorca, nobena od teh ocen ne upošteva natančno, kako so podatki porazdeljeni. Varianca in standardni odklon brez te pomanjkljivosti. Ti kazalniki vam omogočajo, da ocenite stopnjo nihanja podatkov okoli povprečja. Varianca vzorca je približek aritmetične sredine, izračunane iz kvadratov razlik med vsakim vzorčnim elementom in vzorčno sredino. Za vzorec X 1 , X 2 , ... X n je vzorčna varianca (označena s simbolom S 2 ) podana z naslednjo formulo:

Na splošno je vzorčna varianca vsota kvadratov razlik med vzorčnimi elementi in vzorčno sredino, deljena z vrednostjo, ki je enaka velikosti vzorca minus ena:

kje - aritmetična sredina, n- Velikost vzorca, X i - jaz-th vzorčni element X. V Excelu pred različico 2007 je bila za izračun vzorčne variance uporabljena funkcija =VAR(), od različice 2010 pa funkcija =VAR.V().
Najbolj praktična in splošno sprejeta ocena razpršenosti podatkov je standardni odklon. Ta indikator je označen s simbolom S in je enak kvadratni koren iz vzorčne variance:

V Excelu pred različico 2007 je bila za izračun standardnega odklona uporabljena funkcija =STDEV(), od različice 2010 dalje pa se uporablja funkcija =STDEV.B(). Za izračun teh funkcij je lahko podatkovno polje neurejeno.
Niti vzorčna varianca niti vzorčni standardni odklon ne moreta biti negativna. Edina situacija, v kateri sta indikatorja S 2 in S lahko enaka nič, je, če so vsi elementi vzorca enaki. V tem povsem neverjetnem primeru sta tudi razpon in interkvartilni razpon nič.
Numerični podatki so sami po sebi spremenljivi. Vsaka spremenljivka lahko zavzame veliko različnih vrednosti. Na primer, različni vzajemni skladi imajo različne stopnje donosa in izgube. Zaradi variabilnosti numeričnih podatkov je zelo pomembno preučevati ne le ocene povprečja, ki so po naravi sumativne, temveč tudi ocene variance, ki označujejo razpršenost podatkov.
Varianca in standardni odklon nam omogočata, da ocenimo širjenje podatkov okoli povprečja, z drugimi besedami, da ugotovimo, koliko elementov vzorca je manjših od povprečja in koliko večjih. Disperzija ima nekaj dragocenih matematičnih lastnosti. Vendar je njegova vrednost kvadrat merske enote - kvadratni odstotek, kvadratni dolar, kvadratni palec itd. Zato je naravna ocena variance standardna deviacija, ki je izražena v običajnih merskih enotah – odstotkih dohodka, dolarjih ali palcih.
Standardni odklon vam omogoča, da ocenite količino nihanja vzorčnih elementov okoli srednje vrednosti. V skoraj vseh situacijah je večina opazovanih vrednosti znotraj plus ali minus enega standardnega odklona od povprečja. Zato je ob poznavanju aritmetične sredine vzorčnih elementov in standardnega vzorčnega odklona mogoče določiti interval, ki mu pripada glavnina podatkov.
Standardni odklon donosov 15 zelo tveganih vzajemnih skladov je 6,6 (slika 9). To pomeni, da se donosnost večine skladov od povprečne vrednosti razlikuje za največ 6,6 % (tj. niha v območju od – S= 6,2 – 6,6 = –0,4 do +S= 12,8). Pravzaprav ta interval vsebuje petletno povprečno letno donosnost 53,3 % (8 od 15) sredstev.

riž. 9. Standardni odklon
Upoštevajte, da v procesu seštevanja kvadratov razlik postavke, ki so dlje od povprečja, pridobijo večjo težo kot postavke, ki so bližje. Ta lastnost je glavni razlog, zakaj se aritmetična sredina najpogosteje uporablja za oceno srednje vrednosti porazdelitve.
Koeficient variacije
Za razliko od prejšnjih ocen razpršitve je koeficient variacije relativna ocena. Vedno se meri kot odstotek, ne v izvirnih podatkovnih enotah. Koeficient variacije, označen s simboli CV, meri razpršitev podatkov okoli srednje vrednosti. Koeficient variacije je enak standardni deviaciji, deljeni z aritmetično sredino in pomnoženi s 100 %:

kje S- standardni odklon vzorca, - povprečje vzorca.
Koeficient variacije omogoča primerjavo dveh vzorcev, katerih elementi so izraženi v različnih merskih enotah. Na primer, vodja službe za dostavo pošte namerava nadgraditi vozni park tovornjakov. Pri nalaganju paketov je treba upoštevati dve vrsti omejitev: težo (v funtih) in prostornino (v kubičnih čevljih) vsakega paketa. Predpostavimo, da je v vzorcu 200 vrečk povprečna teža 26,0 funtov, standardni odklon teže 3,9 funtov, povprečna prostornina paketa 8,8 kubičnih čevljev in standardni odklon prostornine 2,2 kubičnih čevljev. Kako primerjati razpon teže in prostornine paketov?
Ker se merske enote za težo in prostornino med seboj razlikujejo, mora vodja primerjati relativno razpršenost teh vrednosti. Koeficient variacije teže je CV W = 3,9 / 26,0 * 100 % = 15 %, koeficient variacije prostornine pa CV V = 2,2 / 8,8 * 100 % = 25 %. Tako je relativna razpršenost prostornine paketov veliko večja od relativne razpršenosti njihovih uteži.
Obrazec za distribucijo
Tretja pomembna lastnost vzorca je oblika njegove porazdelitve. Ta porazdelitev je lahko simetrična ali asimetrična. Za opis oblike porazdelitve je treba izračunati njeno povprečje in mediano. Če sta ti dve meri enaki, pravimo, da je spremenljivka simetrično porazdeljena. Če je srednja vrednost spremenljivke večja od mediane, ima njena porazdelitev pozitivno asimetrijo (slika 10). Če je mediana večja od povprečja, je porazdelitev spremenljivke negativno poševna. Pozitivna asimetrija se pojavi, ko se povprečje poveča na nenavadno visoke vrednosti. Negativna asimetrija se pojavi, ko se povprečje zmanjša na nenavadno majhne vrednosti. Spremenljivka je simetrično porazdeljena, če ne zavzame nobenih ekstremnih vrednosti v nobeni smeri, tako da se velike in majhne vrednosti spremenljivke medsebojno izničijo.

riž. 10. Tri vrste distribucij
Podatki, prikazani na lestvici A, imajo negativno asimetrijo. Ta slika prikazuje dolg rep in poševnost v levo, ki jo povzroči prisotnost nenavadno majhnih vrednosti. Te izjemno majhne vrednosti premaknejo srednjo vrednost v levo in postane manjša od mediane. Podatki, prikazani na lestvici B, so porazdeljeni simetrično. Leva in desna polovica porazdelitve sta njihovi zrcalni podobi. Velike in majhne vrednosti se uravnotežijo, povprečje in mediana pa sta enaki. Podatki, prikazani na lestvici B, imajo pozitivno asimetrijo. Ta slika prikazuje dolg rep in poševnost v desno, ki je posledica prisotnosti nenavadno visokih vrednosti. Te prevelike vrednosti premaknejo povprečje v desno in postane večje od mediane.
V Excelu je mogoče z dodatkom pridobiti opisno statistiko Paket analize. Pojdite skozi meni podatki → Analiza podatkov, v oknu, ki se odpre, izberite vrstico Opisna statistika in kliknite V redu. V oknu Opisna statistika obvezno navedite vnosni interval(Slika 11). Če želite videti opisno statistiko na istem listu kot izvirni podatki, izberite izbirni gumb izhodni interval in določite celico, kamor želite postaviti zgornji levi kot prikazane statistike (v našem primeru $C$1). Če želite izpisati podatke na nov list ali v nov delovni zvezek, preprosto izberite ustrezen izbirni gumb. Potrdite polje zraven Končna statistika. Po želji lahko tudi izbirate težavnostna stopnja,k-ti najmanjši ink-to največje.
Če na depozit podatki na območju Analiza ne vidite ikone Analiza podatkov, morate najprej namestiti dodatek Paket analize(glej na primer).

riž. 11. Opisna statistika petletnih povprečnih letnih donosov skladov z zelo visokimi stopnjami tveganja, izračunanih z dodatkom Analiza podatkov Excel programi
Excel izračuna številne zgoraj obravnavane statistike: povprečje, mediano, način, standardni odklon, varianco, razpon ( interval), najmanjša, največja in velikost vzorca ( preverite). Poleg tega Excel za nas izračuna nekaj novih statističnih podatkov: standardno napako, kurtozo in asimetrijo. standardna napaka je enak standardnemu odklonu, deljenemu s kvadratnim korenom velikosti vzorca. Asimetrija označuje odstopanje od simetrije porazdelitve in je funkcija, ki je odvisna od kuba razlik med elementi vzorca in srednje vrednosti. Kurtoza je merilo relativne koncentracije podatkov okoli povprečja v primerjavi z repi porazdelitve in je odvisno od razlik med vzorcem in povprečjem, dvignjenim na četrto potenco.
Izračun deskriptivne statistike za splošno populacijo
Povprečna vrednost, razpršenost in oblika zgoraj obravnavane porazdelitve so značilnosti, ki temeljijo na vzorcu. Če pa nabor podatkov vsebuje numerične meritve celotne populacije, je mogoče izračunati njene parametre. Ti parametri vključujejo povprečje, varianco in standardni odklon populacije.
Pričakovana vrednost je enaka vsoti vseh vrednosti splošne populacije, deljene z obsegom splošne populacije:

kje µ - pričakovana vrednost, Xjaz- jaz-th spremenljivka opazovanje X, n- obseg splošne populacije. V Excelu se za izračun matematičnega pričakovanja uporablja ista funkcija kot za aritmetično sredino: =AVERAGE().
Varianca populacije enaka vsoti kvadratov razlik med elementi generalne populacije in mat. pričakovanje deljeno z velikostjo populacije:

kje σ2 je varianca splošne populacije. Excel pred različico 2007 uporablja funkcijo =VAR() za izračun variance populacije, začenši z različico 2010 =VAR.G().
populacijski standardni odklon je enak kvadratnemu korenu variance populacije:

Excel pred različico 2007 uporablja =STDEV() za izračun standardnega odklona populacije, začenši z različico 2010 =STDEV.Y(). Upoštevajte, da se formule za varianco populacije in standardni odklon razlikujejo od formul za varianco vzorca in standardni odklon. Pri izračunu vzorčne statistike S2 in S imenovalec ulomka je n - 1, in pri izračunu parametrov σ2 in σ - obseg splošne populacije n.
osnovno pravilo
V večini primerov je velik delež opazovanj skoncentriran okoli mediane in tvori skupino. V nizih podatkov s pozitivno asimetrijo se ta grozd nahaja levo (tj. pod) matematičnim pričakovanjem, v nizih z negativno asimetrijo pa se ta gruče nahaja desno (tj. zgoraj) od matematičnega pričakovanja. Simetrični podatki imajo enako povprečje in mediano, opazovanja pa se združujejo okoli povprečja in tvorijo zvonasto porazdelitev. Če porazdelitev nima izrazite asimetrije in so podatki koncentrirani okoli določenega težišča, lahko za oceno variabilnosti uporabimo pravilo, ki pravi: če imajo podatki zvonasto porazdelitev, potem približno 68 % opazovanj je znotraj enega standardnega odklona matematičnega pričakovanja, Približno 95 % opazovanj je znotraj dveh standardnih odklonov pričakovane vrednosti in 99,7 % opazovanj je znotraj treh standardnih odklonov pričakovane vrednosti.
Tako standardni odklon, ki je ocena povprečnega nihanja okoli matematičnega pričakovanja, pomaga razumeti, kako so opazovanja porazdeljena, in prepoznati odstopanja. Iz osnovnega pravila izhaja, da se za zvonaste porazdelitve samo ena vrednost od dvajsetih razlikuje od matematičnega pričakovanja za več kot dva standardna odklona. Zato so vrednosti zunaj intervala µ ± 2σ, se lahko štejejo za izstopajoče. Poleg tega se samo tri od 1000 opazovanj razlikujejo od matematičnega pričakovanja za več kot tri standardne deviacije. Torej vrednosti izven intervala µ ± 3σ so skoraj vedno izstopajoči. Za porazdelitve, ki so zelo poševne ali niso zvonaste, je mogoče uporabiti pravilo Biename-Chebyshev.
Pred več kot sto leti sta neodvisno odkrila matematika Bienamay in Chebyshev uporabna lastnina standardni odklon. Ugotovili so, da za kateri koli niz podatkov, ne glede na obliko porazdelitve, odstotek opazovanj, ki ležijo na razdalji, ki ne presega k standardni odkloni od matematičnega pričakovanja, ne manj (1 – 1/ 2)*100 %.
Na primer, če k= 2, pravilo Biename-Chebysheva navaja, da mora vsaj (1 - (1/2) 2) x 100 % = 75 % opazovanj ležati v intervalu µ ± 2σ. To pravilo velja za vse k presega eno. Pravilo Biename-Chebyshev je zelo splošne narave in velja za distribucije katere koli vrste. Označuje najmanjše število opazovanj, od katerih razdalja do matematičnega pričakovanja ne presega dane vrednosti. Če pa je porazdelitev v obliki zvona, pravilo natančneje oceni koncentracijo podatkov okoli povprečja.
Računanje deskriptivne statistike za porazdelitev na podlagi frekvence
Če izvirni podatki niso na voljo, postane frekvenčna porazdelitev edini vir informacij. V takšnih situacijah lahko izračunate približne vrednosti kvantitativnih kazalcev porazdelitve, kot so aritmetična sredina, standardni odklon, kvartili.
Če so vzorčni podatki predstavljeni kot frekvenčna porazdelitev, je mogoče izračunati približno vrednost aritmetične sredine ob predpostavki, da so vse vrednosti v vsakem razredu koncentrirane na sredini razreda:

kje - povprečje vzorca, n- število opazovanj ali velikost vzorca, z- število razredov v frekvenčni porazdelitvi, mj- srednja točka j- razred, fj- frekvenca, ki ustreza j- razred.
Za izračun standardnega odklona od frekvenčne porazdelitve se tudi predpostavlja, da so vse vrednosti znotraj vsakega razreda koncentrirane na sredini razreda.

Da bi razumeli, kako so določeni kvartili serije na podlagi frekvenc, razmislimo o izračunu spodnjega kvartila na podlagi podatkov za leto 2013 o porazdelitvi ruskega prebivalstva glede na povprečni denarni dohodek na prebivalca (slika 12).

riž. 12. Delež prebivalstva Rusije z denarnim dohodkom na prebivalca v povprečju na mesec, rubljev
Za izračun prvega kvartila niza intervalnih variacij lahko uporabite formulo:

kjer je Q1 vrednost prvega kvartila, xQ1 je spodnja meja intervala, ki vsebuje prvi kvartil (interval je določen z akumulirano frekvenco, prva presega 25 %); i je vrednost intervala; Σf je vsota frekvenc celotnega vzorca; verjetno vedno enako 100 %; SQ1–1 je kumulativna frekvenca intervala pred intervalom, ki vsebuje spodnji kvartil; fQ1 je frekvenca intervala, ki vsebuje spodnji kvartil. Formula za tretji kvartil se razlikuje po tem, da morate na vseh mestih namesto Q1 uporabiti Q3 in namesto ¼ nadomestiti ¾.
V našem primeru (slika 12) je spodnji kvartil v območju 7000,1 - 10.000, katerega kumulativna frekvenca je 26,4 %. Spodnja meja tega intervala je 7000 rubljev, vrednost intervala je 3000 rubljev, akumulirana frekvenca intervala pred intervalom, ki vsebuje spodnji kvartil, je 13,4%, frekvenca intervala, ki vsebuje spodnji kvartil, je 13,0%. Tako: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 rubljev.
Pasti, povezane z opisno statistiko
V tej opombi smo pogledali, kako opisati nabor podatkov z uporabo različnih statistik, ki ocenjujejo njegovo povprečje, razpršitev in porazdelitev. naslednji korak je analiza in interpretacija podatkov. Doslej smo preučevali objektivne lastnosti podatkov, zdaj pa se posvetimo njihovi subjektivni interpretaciji. Raziskovalca čakata dve napaki: nepravilno izbran predmet analize in nepravilna interpretacija rezultatov.
Analiza uspešnosti 15 vzajemnih skladov z zelo visokim tveganjem je dokaj nepristranska. Pripeljal je do povsem objektivnih zaključkov: vsi vzajemni skladi imajo različne donose, razpon donosov skladov se giblje od -6,1 do 18,5, povprečna donosnost pa je 6,08. Zagotovljena je objektivnost analize podatkov prava izbira skupni kvantitativni kazalniki distribucije. Obravnavanih je bilo več metod za ocenjevanje povprečja in razpršenosti podatkov ter prikazane njihove prednosti in slabosti. Kako izbrati pravo statistiko, ki zagotavlja objektivno in nepristransko analizo? Če je porazdelitev podatkov rahlo poševna, ali je treba izbrati mediano namesto aritmetične sredine? Kateri indikator natančneje označuje širjenje podatkov: standardni odklon ali razpon? Ali je treba navesti pozitivno asimetrijo porazdelitve?
Po drugi strani pa je interpretacija podatkov subjektiven proces. Različni ljudje prihajajo do različnih zaključkov in razlagajo iste rezultate. Vsak ima svoje stališče. Nekdo meni, da so skupni povprečni letni donosi 15 skladov z zelo visoko stopnjo tveganja dobri in je zelo zadovoljen s prejetim dohodkom. Drugi morda mislijo, da imajo ti skladi prenizke donose. Tako je treba subjektivnost nadomestiti s poštenostjo, nevtralnostjo in jasnostjo sklepov.
Etična vprašanja
Analiza podatkov je neločljivo povezana z etičnimi vprašanji. Do informacij, ki jih širijo časopisi, radio, televizija in internet, je treba biti kritičen. Sčasoma se boste naučili biti skeptični ne le do rezultatov, temveč tudi do ciljev, predmeta in objektivnosti raziskovanja. Slavna oseba je to najbolje povedala britanski politik Benjamin Disraeli: "Obstajajo tri vrste laži: laži, preklete laži in statistika."
Kot je navedeno v opombi, se pri izbiri rezultatov, ki naj bodo predstavljeni v poročilu, pojavijo etična vprašanja. Objaviti je treba tako pozitivne kot negativne rezultate. Poleg tega morajo biti pri izdelavi poročila ali pisnega poročila rezultati predstavljeni pošteno, nevtralno in objektivno. Razlikujte med slabimi in nepoštenimi predstavitvami. Za to je treba ugotoviti, kakšni so bili nameni govorca. Včasih govorec pomembne informacije izpusti iz nevednosti, včasih pa namenoma (na primer, če uporabi aritmetično sredino za oceno sredine očitno izkrivljenih podatkov, da bi dobil želeni rezultat). Nepošteno je tudi zamolčanje rezultatov, ki ne ustrezajo zornemu kotu raziskovalca.
Uporabljeno je gradivo iz knjige Levin et al. Statistika za managerje. - M.: Williams, 2004. - str. 178–209
Funkcija QUARTILE je ohranjena zaradi uskladitve s starejšimi različicami Excela
Znaki enot statističnih agregatov so različni po pomenu, na primer plače delavcev enega poklica v podjetju niso enake za isto časovno obdobje, tržne cene za iste proizvode so različne, pridelek na kmetijah regije itd. Zato se za določitev vrednosti značilnosti, značilne za celotno populacijo proučevanih enot, izračunajo povprečne vrednosti.
Povprečna vrednost –
je posplošujoča značilnost nabora posameznih vrednosti neke kvantitativne lastnosti.
Populacija, ki jo preučuje kvantitativni atribut, je sestavljena iz posameznih vrednosti; nanje vplivajo tako splošni vzroki kot posamezna stanja. V povprečni vrednosti se odstopanja, značilna za posamezne vrednosti, izničijo. Povprečje, ki je funkcija nabora posameznih vrednosti, predstavlja celoten niz z eno vrednostjo in odraža skupno stvar, ki je lastna vsem njegovim enotam.
Povprečje, izračunano za populacije, sestavljene iz kvalitativno homogenih enot, se imenuje tipično povprečje. Na primer, lahko izračunate povprečno mesečno plačo zaposlenega v eni ali drugi poklicni skupini (rudar, zdravnik, knjižničar). Seveda se višine mesečnih plač rudarjev zaradi razlike v njihovi izobrazbi, delovni dobi, opravljenih urah na mesec in številnih drugih dejavnikov razlikujejo med seboj in od višine povprečnih plač. Vendar pa povprečna raven odraža glavne dejavnike, ki vplivajo na višino plače, in medsebojno kompenzira razlike, ki nastanejo zaradi individualnih značilnosti zaposlenega. Povprečna plača odraža tipično raven plače za to vrsto delavcev. Pred pridobitvijo tipičnega povprečja je treba analizirati, kako kakovostno je ta populacija homogena. Če je populacija sestavljena iz ločenih delov, jo je treba razdeliti na tipične skupine (povprečna temperatura v bolnišnici).
Imenujejo se povprečne vrednosti, ki se uporabljajo kot značilnosti za heterogene populacije sistemska povprečja. Na primer povprečje bruto domači proizvod(BDP) na prebivalca, povprečna vrednost potrošnje različnih skupin blaga na osebo in druge podobne vrednosti, ki predstavljajo splošne značilnosti države kot enotnega gospodarskega sistema.
Povprečje je treba izračunati za populacije, ki jih sestavlja dovolj veliko število enote. Izpolnjevanje tega pogoja je potrebno za uveljavitev zakona. velike številke, zaradi česar se naključna odstopanja posameznih vrednosti od splošnega trenda med seboj izničijo.
Vrste povprečij in metode za njihov izračun
Izbira vrste povprečja je odvisna od ekonomske vsebine določenega kazalnika in začetnih podatkov. Vendar pa je treba vsako povprečno vrednost izračunati tako, da se, ko nadomesti vsako različico povprečne lastnosti, končna, posplošljiva ali, kot se običajno imenuje, ne spremeni. opredelitveni indikator, kar je povezano s povprečjem. Na primer, pri zamenjavi dejanskih hitrosti na posameznih odsekih poti njihova povprečna hitrost ne sme spremeniti skupne prevožene razdalje vozilo ob istem času; pri nadomestitvi dejanskih plač posameznih zaposlenih v podjetju s povprečno plačo se sklad plač ne bi smel spremeniti. Posledično je v vsakem posameznem primeru, odvisno od narave razpoložljivih podatkov, le ena prava povprečna vrednost kazalnika, ki ustreza lastnostim in bistvu proučevanega družbeno-ekonomskega pojava.
Najpogosteje uporabljene so aritmetična sredina, harmonična sredina, geometrična sredina, kvadratna sredina in kubična sredina.
Navedena povprečja sodijo v razred moč povprečje in so združeni s splošno formulo:
,
kjer je povprečna vrednost proučevane lastnosti;
m je eksponent srednje vrednosti;
– trenutna vrednost (varianta) povprečene lastnosti;
n je število funkcij.
Glede na vrednost eksponenta m ločimo naslednje vrste povprečij moči:
pri m = -1 – povprečje harmonika ;
pri m = 0 – geometrična sredina ;
pri m = 1 – aritmetična sredina;
pri m = 2 – povprečni kvadratni koren ;
pri m = 3 - povprečna kubična.
Pri uporabi istih začetnih podatkov, večji kot je eksponent m v zgornji formuli, večja je vrednost povprečne vrednosti:
.
Ta lastnost potenčnega zakona pomeni povečanje s povečanjem eksponenta definirajoče funkcije se imenuje pravilo večine sredstev.
Vsako od označenih povprečij ima lahko dve obliki: preprosto in tehtano.
Preprosta oblika sredine velja, kadar je povprečje izračunano na podlagi primarnih (nezdruženih) podatkov. utežena oblika– pri izračunu povprečja za sekundarne (združene) podatke.
Aritmetična sredina
Aritmetična sredina se uporablja, kadar je obseg populacije vsota vseh posameznih vrednosti spremenljivega atributa. Upoštevati je treba, da če vrsta povprečja ni navedena, se predpostavlja aritmetično povprečje. Njegova logična formula je: ![]()
enostavna aritmetična sredina izračunano po nezdruženih podatkih
po formuli: ![]() ali,
ali,
kje so posamezne vrednosti atributa;
j je zaporedna številka enote opazovanja, ki jo označuje vrednost ;
N je število enot opazovanja (velikost niza).
Primer. V predavanju »Povzetek in združevanje statističnih podatkov« so bili obravnavani rezultati opazovanja delovnih izkušenj ekipe 10 ljudi. Izračunajte povprečne delovne izkušnje delavcev brigade. 5, 3, 5, 4, 3, 4, 5, 4, 2, 4.
Po formuli enostavne aritmetične sredine se tudi izračuna kronološka povprečja, če so časovni intervali, za katere so predstavljene karakteristične vrednosti, enaki.
Primer. Obseg prodanih izdelkov za prvo četrtletje je znašal 47 den. enot, za drugo 54, za tretjo 65 in za četrto 58 den. enote Povprečni četrtletni promet je (47+54+65+58)/4 = 56 den. enote
Če so trenutni kazalniki podani v kronološki seriji, se pri izračunu povprečja nadomestijo s polovičnimi vsotami vrednosti na začetku in koncu obdobja.
Če sta trenutka več kot dva in so intervali med njima enaki, se povprečje izračuna po formuli za povprečno kronološko
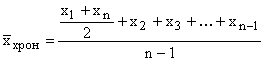 ,
,
kjer je n število časovnih točk
Ko so podatki razvrščeni po vrednostih atributov
(tj. konstruirana je diskretna serija variacijske porazdelitve) s utežena aritmetična sredina se izračuna z uporabo bodisi frekvenc ali frekvenc opazovanja specifičnih vrednosti lastnosti, katerih število (k) je pomembno manj kot številka opažanja (N) .
,
,
kjer je k število skupin variacijske serije,
i je številka skupine variacijske serije.
Ker , in , dobimo formule, ki se uporabljajo za praktične izračune:
in
Primer. Izračunajmo povprečno delovno dobo delovnih skupin za združene serije.
a) z uporabo frekvenc:
b) z uporabo frekvenc:
Ko so podatki razvrščeni po intervalih
, tj. so predstavljene v obliki nizov intervalne porazdelitve, pri čemer se pri izračunu aritmetične sredine kot vrednost znaka vzame sredina intervala, ki temelji na predpostavki enakomerne porazdelitve populacijskih enot v tem intervalu. Izračun se izvede po formulah:
in
kjer je sredina intervala: ,
kjer sta in spodnja in zgornja meja intervalov (pod pogojem, da zgornja meja tega intervala sovpada s spodnjo mejo naslednjega intervala).
Primer. Izračunajmo aritmetično sredino intervalne variacijske serije, sestavljene iz rezultatov študije letnih plač 30 delavcev (glej predavanje "Povzetek in grupiranje statističnih podatkov").
Tabela 1 - Intervalne variacijske serije porazdelitve.
Intervali, UAH |
Pogostost, os. |
frekvenca, |
Sredina intervala |
||
600-700 |
3 |
0,10 |
(600+700):2=650 |
1950 |
65 |
![]() UAH oz
UAH oz ![]() UAH
UAH
Aritmetične sredine, izračunane na podlagi začetnih podatkov in serije intervalnih variacij, morda ne sovpadajo zaradi neenakomerne porazdelitve vrednosti atributov znotraj intervalov. V tem primeru za natančnejši izračun aritmetičnega tehtanega povprečja ne bi smeli uporabiti sredine intervalov, temveč aritmetična enostavna povprečja, izračunana za vsako skupino ( skupinska povprečja). Povprečje, izračunano iz skupinskih povprečij z uporabo utežene formule za izračun, se imenuje generalna povprečja.
Aritmetična sredina ima številne lastnosti.
1. Vsota odstopanj variante od povprečja je nič:
.
2. Če se vse vrednosti možnosti povečajo ali zmanjšajo za vrednost A, se povprečna vrednost poveča ali zmanjša za isto vrednost A: ![]()
3. Če se vsaka možnost poveča ali zmanjša za B-krat, se bo tudi povprečna vrednost povečala ali zmanjšala za enako število-krat:
oz ![]()
4. Vsota zmnožkov variant po frekvencah je enaka zmnožku povprečne vrednosti z vsoto frekvenc: ![]()
5. Če vse frekvence delimo ali pomnožimo s poljubnim številom, se aritmetična sredina ne spremeni: 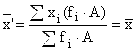
6) če so v vseh intervalih frekvence med seboj enake, potem je aritmetično tehtano povprečje enako preprostemu aritmetičnemu povprečju: ![]() ,
,
kjer je k število skupin v variacijski seriji.
Uporaba lastnosti povprečja vam omogoča poenostavitev njegovega izračuna.
Recimo, da so vse možnosti (x) najprej zmanjšane za isto število A in nato zmanjšane za faktor B. Največjo poenostavitev dosežemo, če izberemo vrednost sredine intervala z najvišjo frekvenco kot A, vrednost intervala pa kot B (za vrstice z enakimi intervali). Količina A se imenuje izvor, zato se imenuje ta način izračuna povprečja način b ohm referenca od pogojne ničle oz način trenutkov.
Po takšni transformaciji dobimo novo variacijsko porazdelitveno vrsto, katere različice so enake . Njihova aritmetična sredina, imenovana trenutek prvega reda, je izražena s formulo in glede na drugo in tretjo lastnost je aritmetična sredina enaka sredini prvotne različice, zmanjšani najprej za A, nato pa za B-krat, tj.
Za pridobitev realno povprečje(sredina prvotne vrstice) morate trenutek prvega reda pomnožiti z B in dodati A: 
Izračun aritmetične sredine po metodi momentov ponazarjajo podatki v tabeli. 2.
Tabela 2 - Porazdelitev zaposlenih v podjetniški trgovini po delovni dobi
Delovne izkušnje, leta |
Količina delavcev |
Srednja točka intervala |
|||
0 – 5 |
12 |
2,5 |
15 |
3 |
36 |
Iskanje trenutka prvega reda ![]() . Potem, ko vemo, da je A = 17,5 in B = 5, izračunamo povprečne delovne izkušnje delavcev v trgovini:
. Potem, ko vemo, da je A = 17,5 in B = 5, izračunamo povprečne delovne izkušnje delavcev v trgovini:
leta
Povprečna harmonika
Kot je prikazano zgoraj, se aritmetična sredina uporablja za izračun povprečne vrednosti lastnosti v primerih, ko so znane njene različice x in njihove frekvence f.
Če statistični podatki ne vsebujejo frekvenc f za posamezne možnosti x populacije, ampak so predstavljeni kot njihov produkt, se uporabi formula povprečno harmonično tehtano. Za izračun povprečja označimo , od koder . Če te izraze nadomestimo s formulo za uteženo aritmetično sredino, dobimo formulo za uteženo harmonično sredino:  ,
,
kjer je obseg (teža) vrednosti atributa indikatorja v intervalu s številko i (i=1,2, …, k).
Tako se harmonično povprečje uporablja v primerih, ko se seštevajo ne same opcije, temveč njihove recipročne vrednosti: ![]() .
.
V primerih, ko je teža vsake opcije enaka ena, tj. posamezne vrednosti inverzne lastnosti se pojavijo enkrat, veljajo preprosto harmonično povprečje: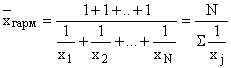 ,
,
kjer so posamezne različice inverzne lastnosti, ki se pojavijo enkrat;
N je število možnosti.
Če obstajata harmonična povprečja za dva dela populacije s številom in, se skupno povprečje za celotno populacijo izračuna po formuli: 
in poklical uteženo harmonično povprečje skupinskih povprečij.
Primer. V prvi uri trgovanja na borzi so bili sklenjeni trije posli. Podatki o količini prodaje grivne in tečaju grivne glede na ameriški dolar so podani v tabeli. 3 (stolpca 2 in 3). Določite povprečni menjalni tečaj grivne glede na ameriški dolar v prvi uri trgovanja.
Tabela 3 - Podatki o poteku trgovanja na borzi
Povprečni menjalni tečaj dolarja je določen z razmerjem med količino grivn, prodanih med vsemi transakcijami, in količino dolarjev, pridobljenih kot rezultat istih transakcij. Skupni znesek prodaje grivne je znan iz stolpca 2 tabele, znesek dolarjev, kupljenih v vsaki transakciji, pa se določi tako, da se znesek prodaje grivne deli z menjalnim tečajem (stolpec 4). Med tremi transakcijami je bilo kupljenih skupaj 22 milijonov dolarjev. To pomeni, da je bil povprečni menjalni tečaj grivna za en dolar  .
.
Dobljena vrednost je resnična, ker njegova zamenjava dejanskih menjalnih tečajev grivne v transakcijah ne bo spremenila skupnega zneska prodaje grivne, ki deluje kot opredelitveni indikator: milijonov UAH
Če je bila za izračun uporabljena aritmetična sredina, tj. ![]() grivna, nato pa po menjalnem tečaju za nakup 22 milijonov dolarjev. Porabiti bi bilo treba 110,66 milijona UAH, kar ne drži.
grivna, nato pa po menjalnem tečaju za nakup 22 milijonov dolarjev. Porabiti bi bilo treba 110,66 milijona UAH, kar ne drži.
Geometrijska sredina
Geometrična sredina se uporablja za analizo dinamike pojavov in vam omogoča, da določite povprečno stopnjo rasti. Pri izračunu geometrične sredine so posamezne vrednosti atributa relativni kazalniki dinamike, zgrajene v obliki verižnih vrednosti, kot razmerje med vsako stopnjo in prejšnjo.
Geometrijska enostavna sredina se izračuna po formuli: 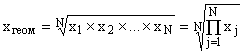 ,
,
kje je znak izdelka,
N je število povprečnih vrednosti.
Primer.Število registriranih kaznivih dejanj v 4 letih se je povečalo za 1,57-krat, od tega za 1. - za 1,08-krat, za 2. - za 1,1-krat, za 3. - za 1,18 in za 4. - 1,12-krat. Potem je povprečna letna stopnja rasti števila kaznivih dejanj: , tj. Število registriranih kaznivih dejanj se v povprečju letno povečuje za 12 %.
1,8
-0,8
0,2
1,0
1,4
1
3
4
1
1
3,24
0,64
0,04
1
1,96
3,24
1,92
0,16
1
1,96
Za izračun srednje kvadratne utežene vrednosti določimo in vnesemo v tabelo in. Potem je povprečna vrednost odstopanj dolžine izdelkov od dane norme enaka: 
Aritmetična sredina bi bila v tem primeru neprimerna, saj posledično bi dobili odstopanje nič.
O uporabi kvadratnega korena bomo razpravljali pozneje pri eksponentih variacije.