
The value of the average value depends on the individual. Summary: Average values used in statistics. Production of workers of the brigade per shift, pcs
The most common type of average is the arithmetic average.
simple arithmetic mean
The simple arithmetic mean is the average term, in determining which the total volume of a given attribute in the data is equally distributed among all units included in this population. Thus, the average annual output per worker is such a value of the volume of output that would fall on each employee if the entire volume of output was equally distributed among all employees of the organization. The arithmetic mean simple value is calculated by the formula:
simple arithmetic mean— Equal to the ratio of the sum of individual values of a feature to the number of features in the aggregate
Example 1. A team of 6 workers receives 3 3.2 3.3 3.5 3.8 3.1 thousand rubles per month.
Find the average salary
Solution: (3 + 3.2 + 3.3 +3.5 + 3.8 + 3.1) / 6 = 3.32 thousand rubles.
Arithmetic weighted average
If the volume of the data set is large and represents a distribution series, then a weighted arithmetic mean is calculated. This is how the weighted average price per unit of production is determined: the total cost of production (the sum of the products of its quantity and the price of a unit of production) is divided by the total quantity of production.
We represent this in the form of the following formula:
![]()
Weighted arithmetic mean- is equal to the ratio (the sum of the products of the attribute value to the frequency of repetition of this attribute) to (the sum of the frequencies of all attributes). It is used when the variants of the studied population occur an unequal number of times.
Example 2. Find the average wages of shop workers per month
The average wage can be obtained by dividing the total wage by the total number of workers:

Answer: 3.35 thousand rubles.
Arithmetic mean for an interval series
When calculating the arithmetic mean for an interval variation series, the average for each interval is first determined as the half-sum of the upper and lower limits, and then the average of the entire series. In the case of open intervals, the value of the lower or upper interval is determined by the value of the intervals adjacent to them.
Averages calculated from interval series are approximate.
Example 3. Determine the average age of students in the evening department.

Averages calculated from interval series are approximate. The degree of their approximation depends on the extent to which the actual distribution of population units within the interval approaches uniform.
When calculating averages, not only absolute, but also relative values (frequency) can be used as weights:
The arithmetic mean has a number of properties that more fully reveal its essence and simplify the calculation:
1. The product of the average and the sum of the frequencies is always equal to the sum of the products of the variant and the frequencies, i.e.
![]()
2. The arithmetic mean of the sum of the varying values is equal to the sum of the arithmetic means of these values:
3. The algebraic sum of the deviations of the individual values of the attribute from the average is zero.
average value- this is a generalizing indicator that characterizes a qualitatively homogeneous population according to a certain quantitative attribute. For example, the average age of persons convicted of theft.
In judicial statistics, averages are used to characterize:
Average terms of consideration of cases of this category;
Medium size claim;
The average number of defendants per case;
Average amount of damage;
Average workload of judges, etc.
The average value is always named and has the same dimension as the attribute of a separate unit of the population. Each average value characterizes the studied population according to any one varying attribute, therefore, behind any average, there is a series of distribution of units of this population according to the studied attribute. The choice of the type of average is determined by the content of the indicator and the initial data for calculating the average.
All types of averages used in statistical studies fall into two categories:
1) power averages;
2) structural averages.
The first category of averages includes: arithmetic mean, harmonic mean, geometric mean and root mean square . The second category is fashion and median. Moreover, each of the listed types of power averages can have two forms: simple and weighted . simple form mean value is used to obtain the average value of the studied trait when the calculation is carried out on ungrouped statistical data, or when each variant in the population occurs only once. Weighted averages are values that take into account that the options for the values of a feature can have different numbers, and therefore each option has to be multiplied by the corresponding frequency. In other words, each option is "weighed" by its frequency. The frequency is called the statistical weight.
simple arithmetic mean- the most common type of medium. It is equal to the sum of individual characteristic values divided by the total number of these values:
where x 1 ,x 2 , … ,x N- individual values of the variable attribute (options), and N - the number of population units.
Arithmetic weighted average used when the data is presented in the form of distribution series or groupings. It is calculated as the sum of the products of the options and their corresponding frequencies, divided by the sum of the frequencies of all options:
where x i- meaning i-th variants of the feature; fi- frequency i th options.
Thus, each variant value is weighted by its frequency, which is why the frequencies are sometimes called statistical weights.
Comment. When it comes to the arithmetic mean without specifying its type, the simple arithmetic mean is meant.
Table 12
Solution. For the calculation, we use the formula of the arithmetic weighted average:
Thus, on average, there are two defendants per criminal case.
If the calculation of the average value is carried out according to data grouped in the form of interval distribution series, then first you need to determine the median values of each interval x "i, then calculate the average value using the weighted arithmetic mean formula, in which x" i is substituted instead of x i.
Example. Data on the age of criminals convicted of theft are presented in the table:
Table 13
Determine the average age of criminals convicted of theft.
Solution. In order to determine the average age of criminals based on the interval variation series, you must first find the median values of the intervals. Since an interval series with open first and last intervals is given, the values of these intervals are taken equal to the values of adjacent closed intervals. In our case, the value of the first and last intervals are 10.
Now we find the average age of criminals using the weighted arithmetic mean formula:
Thus, the average age of offenders convicted of theft is approximately 27 years.
Average harmonic simple is the reciprocal of the arithmetic mean of the reciprocal values of the feature:
where 1/ x i are the reciprocals of the options, and N is the number of population units.
Example. In order to determine the average annual workload for judges of a district court when considering criminal cases, a survey was conducted on the workload of 5 judges of this court. The average time spent on one criminal case for each of the surveyed judges turned out to be equal (in days): 6, 0, 5, 6, 6, 3, 4, 9, 5, 4. Find the average costs for one criminal case and the average annual workload on the judges of this district court when considering criminal cases.
Solution. To determine the average time spent on one criminal case, we use the harmonic simple formula:
To simplify the calculations in the example, let's take the number of days in a year equal to 365, including weekends (this does not affect the calculation method, and when calculating a similar indicator in practice, it is necessary to substitute the number of working days in a particular year instead of 365 days). Then the average annual workload for judges of this district court when considering criminal cases will be: 365 (days): 5.56 ≈ 65.6 (cases).
If we used the simple arithmetic mean formula to determine the average time spent on one criminal case, we would get:
365 (days): 5.64 ≈ 64.7 (cases), i.e. the average workload for judges was less.
Let's check the validity of this approach. To do this, we use data on the time spent on one criminal case for each judge and calculate the number of criminal cases considered by each of them per year.
We get accordingly:
365(days) : 6 ≈ 61 (case), 365(days) : 5.6 ≈ 65.2 (case), 365(days) : 6.3 ≈ 58 (case),
365(days) : 4.9 ≈ 74.5 (cases), 365(days) : 5.4 ≈ 68 (cases).
Now we calculate the average annual workload for judges of this district court when considering criminal cases:
Those. the average annual load is the same as when using the harmonic mean.
Thus, the use of the arithmetic mean in this case is illegal.
In cases where the variants of a feature are known, their volumetric values (the product of the variants by the frequency), but the frequencies themselves are unknown, the harmonic weighted average formula is applied:
where x i are the values of the trait options, and w i are the volumetric values of the options ( w i = x i f i).
Example. Data on the price of a unit of the same type of goods produced by various institutions of the penitentiary system, and on the volume of its implementation are given in table 14.
Table 14
Find the average selling price of the product.
Solution. When calculating the average price, we must use the ratio of the amount sold to the number of units sold. We do not know the number of sold units, but we know the amount of sales of goods. Therefore, to find the average price of goods sold, we use the harmonic weighted average formula. We get
If you use the arithmetic mean formula here, you can get an average price that will be unrealistic:
Geometric mean is calculated by extracting the root of degree N from the product of all values of the feature variants:
where x 1 ,x 2 , … ,x N- individual values of the variable trait (options), and
N- number of population units.
This type of average is used to calculate the average growth rates of time series.
root mean square is used to calculate the standard deviation, which is an indicator of variation, and will be discussed below.
To determine the structure of the population, special averages are used, which include median and fashion , or the so-called structural averages. If the arithmetic mean is calculated based on the use of all variants of the attribute values, then the median and mode characterize the value of the variant that occupies a certain average position in the ranked (ordered) series. The ordering of units of the statistical population can be carried out in ascending or descending order of the variants of the trait under study.
Median (Me) is the value that corresponds to the variant in the middle of the ranked series. Thus, the median is that variant of the ranked series, on both sides of which in this series there should be an equal number of population units.
To find the median, you first need to determine its serial number in the ranked series using the formula:
where N is the volume of the series (the number of population units).
If the series consists of an odd number of members, then the median is equal to the variant with the number N Me . If the series consists of an even number of members, then the median is defined as the arithmetic mean of two adjacent options located in the middle.
Example. Given a ranked series 1, 2, 3, 3, 6, 7, 9, 9, 10. The volume of the series is N = 9, which means N Me = (9 + 1) / 2 = 5. Therefore, Me = 6, i.e. . fifth option. If a row is given 1, 5, 7, 9, 11, 14, 15, 16, i.e. series with an even number of members (N = 8), then N Me = (8 + 1) / 2 = 4.5. So the median is equal to half the sum of the fourth and fifth options, i.e. Me = (9 + 11) / 2 = 10.
In a discrete variation series, the median is determined by the accumulated frequencies. Variant frequencies, starting with the first one, are summed until the median number is exceeded. The value of the last summed options will be the median.
Example. Find the median number of defendants per criminal case using the data in Table 12.
Solution. In this case, the volume of the variation series is N = 154, therefore, N Me = (154 + 1) / 2 = 77.5. Summing up the frequencies of the first and second options, we get: 75 + 43 = 118, i.e. we have surpassed the median number. So Me = 2.
In the interval variation series of the distribution, first indicate the interval in which the median will be located. He is called median . This is the first interval whose cumulative frequency exceeds half the volume of the interval variation series. Then the numerical value of the median is determined by the formula:
where x Me- the lower limit of the median interval; i - the value of the median interval; S Me-1- the accumulated frequency of the interval that precedes the median; f Me- frequency of the median interval.
Example. Find the median age of offenders convicted of theft, based on the statistics presented in Table 13.
Solution. Statistical data is represented by an interval variation series, which means that we first determine the median interval. The volume of the population N = 162, therefore, the median interval is the interval 18-28, because this is the first interval, the accumulated frequency of which (15 + 90 = 105) exceeds half the volume (162: 2 = 81) of the interval variation series. Now the numerical value of the median is determined by the above formula:
Thus, half of those convicted of theft are under 25 years old.
Fashion (Mo) name the value of the attribute, which is most often found in units of the population. Fashion is used to identify the value of the trait that has the greatest distribution. For a discrete series, the mode will be the variant with the highest frequency. For example, for a discrete series presented in Table 3 Mo= 1, since this value of the options corresponds to the highest frequency - 75. To determine the mode of the interval series, first determine modal interval (interval having the highest frequency). Then, within this interval, the value of the feature is found, which can be a mode.
Its value is found by the formula:
where x Mo- the lower limit of the modal interval; i - the value of the modal interval; f Mo- modal interval frequency; f Mo-1- frequency of the interval preceding the modal; f Mo+1- frequency of the interval following the modal.
Example. Find the age mode of criminals convicted of theft, data on which are presented in table 13.
Solution. The highest frequency corresponds to the interval 18-28, therefore, the mode must be in this interval. Its value is determined by the above formula:
Thus, the largest number of criminals convicted of theft is 24 years old.
The average value gives a generalizing characteristic of the totality of the phenomenon under study. However, two populations with the same mean values may differ significantly from each other in terms of the degree of fluctuation (variation) in the value of the studied trait. For example, in one court the following terms of imprisonment were assigned: 3, 3, 3, 4, 5, 5, 5, 12, 12, 15 years, and in another - 5, 5, 6, 6, 7, 7, 7 , 8, 8, 8 years old. In both cases, the arithmetic mean is 6.7 years. However, these aggregates differ significantly from each other in the spread of individual values of the assigned term of imprisonment relative to the average value.
And for the first court, where this variation is quite large, the average term of imprisonment does not reflect the whole population well. Thus, if the individual values of the attribute differ little from each other, then the arithmetic mean will be a fairly indicative characteristic of the properties of this population. Otherwise, the arithmetic mean will be an unreliable characteristic of this population and its application in practice is ineffective. Therefore, it is necessary to take into account the variation in the values of the studied trait.
Variation- these are differences in the values of a characteristic in different units of a given population in the same period or point in time. The term "variation" is of Latin origin - variatio, which means difference, change, fluctuation. It arises as a result of the fact that the individual values of the attribute are formed under the combined influence of various factors (conditions), which are combined in different ways in each individual case. To measure the variation of a trait, various absolute and relative indicators are used.
The main indicators of variation include the following:
1) range of variation;
2) average linear deviation;
3) dispersion;
4) standard deviation;
5) coefficient of variation.
Let's briefly dwell on each of them.
Span variation R is the most accessible absolute indicator in terms of ease of calculation, which is defined as the difference between the largest and smallest values of the attribute for units of this population:
The range of variation (range of fluctuations) is an important indicator of the variability of a trait, but it makes it possible to see only extreme deviations, which limits its scope. For a more accurate characterization of the variation of a trait based on its fluctuation, other indicators are used.
Average linear deviation represents the arithmetic mean of the absolute values of the deviations of the individual values of the trait from the mean and is determined by the formulas:
1) for ungrouped data
2) for variation series
However, the most widely used measure of variation is dispersion . It characterizes the measure of the spread of the values of the studied trait relative to its average value. The variance is defined as the average of the deviations squared.
simple variance for ungrouped data:
Weighted variance for the variation series:
Comment. In practice, it is better to use the following formulas to calculate the variance:
For a simple variance
For weighted variance
Standard deviation is the square root of the variance:
The standard deviation is a measure of the reliability of the mean. The smaller the standard deviation, the more homogeneous the population and the better the arithmetic mean reflects the entire population.
The dispersion measures considered above (range of variation, variance, standard deviation) are absolute indicators, by which it is not always possible to judge the degree of fluctuation of a trait. In some problems, it is necessary to use relative scattering indices, one of which is the coefficient of variation.
The coefficient of variation- expressed as a percentage of the ratio of the standard deviation to the arithmetic mean:
The coefficient of variation is used not only for a comparative assessment of the variation of different traits or the same trait in different populations, but also to characterize the homogeneity of the population. The statistical population is considered quantitatively homogeneous if the coefficient of variation does not exceed 33% (for distributions close to the normal distribution).
Example. There is the following data on the terms of imprisonment of 50 convicts delivered to serve the sentence imposed by the court in a correctional institution of the penitentiary system: 5, 4, 2, 1, 6, 3, 4, 3, 2, 2, 5, 6, 4, 3 , 10, 5, 4, 1, 2, 3, 3, 4, 1, 6, 5, 3, 4, 3, 5, 12, 4, 3, 2, 4, 6, 4, 4, 3, 1 , 5, 4, 3, 12, 6, 7, 3, 4, 5, 5, 3.
1. Construct a distribution series by terms of imprisonment.
2. Find the mean, variance and standard deviation.
3. Calculate the coefficient of variation and draw a conclusion about the homogeneity or heterogeneity of the studied population.
Solution. To construct a discrete distribution series, it is necessary to determine the variants and frequencies. The variant in this problem is the term of imprisonment, and the frequency is the number of individual variant. Having calculated the frequencies, we obtain the following discrete distribution series:
Find the mean and variance. Since the statistical data are represented by a discrete variational series, we will use the formulas of the arithmetic weighted average and variance to calculate them. We get:
Now we calculate the standard deviation:
We find the coefficient of variation:
Consequently, the statistical population is quantitatively heterogeneous.
In most cases, the data is concentrated around some central point. Thus, to describe any data set, it is enough to indicate the average value. Consider successively three numerical characteristics that are used to estimate the mean value of the distribution: arithmetic mean, median and mode.
Average
The arithmetic mean (often referred to simply as the mean) is the most common estimate of the mean of a distribution. It is the result of dividing the sum of all observed numerical values by their number. For a sample of numbers X 1, X 2, ..., Xn, the sample mean (denoted by the symbol ) equals \u003d (X 1 + X 2 + ... + Xn) / n, or
where is the sample mean, n- sample size, Xi – i-th element samples.
Download note in or format, examples in format
Consider calculating the arithmetic mean of the five-year average annual returns of 15 mutual funds with very high level risk (Fig. 1).

Rice. 1. Average annual return on 15 very high-risk mutual funds
The sample mean is calculated as follows:

This is a good return, especially when compared to the 3-4% return that bank or credit union depositors received over the same time period. If you sort the return values, it is easy to see that eight funds have a return above, and seven - below the average. The arithmetic mean acts as a balance point, so that low-income funds balance out high-income funds. All elements of the sample are involved in the calculation of the average. None of the other estimators of the distribution mean have this property.
When to calculate the arithmetic mean. Since the arithmetic mean depends on all elements of the sample, the presence of extreme values significantly affects the result. In such situations, the arithmetic mean can distort the meaning of the numerical data. Therefore, when describing a data set containing extreme values, it is necessary to indicate the median or the arithmetic mean and the median. For example, if the return of the RS Emerging Growth fund is removed from the sample, the sample average of the return of the 14 funds decreases by almost 1% to 5.19%.
Median
The median is the middle value of an ordered array of numbers. If the array does not contain repeating numbers, then half of its elements will be less than and half more than the median. If the sample contains extreme values, it is better to use the median rather than the arithmetic mean to estimate the mean. To calculate the median of a sample, it must first be sorted.
This formula is ambiguous. Its result depends on whether the number is even or odd. n:
- If the sample contains an odd number of items, the median is (n+1)/2-th element.
- If the sample contains an even number of elements, the median lies between the two middle elements of the sample and is equal to the arithmetic mean calculated over these two elements.
To calculate the median for a sample of 15 very high-risk mutual funds, we first need to sort the raw data (Figure 2). Then the median will be opposite the number of the middle element of the sample; in our example number 8. Excel has a special function =MEDIAN() that works with unordered arrays too.

Rice. 2. Median 15 funds
Thus, the median is 6.5. This means that half of the very high-risk funds do not exceed 6.5, while the other half do so. Note that the median of 6.5 is slightly larger than the median of 6.08.
If we remove the profitability of the RS Emerging Growth fund from the sample, then the median of the remaining 14 funds will decrease to 6.2%, that is, not as significantly as the arithmetic mean (Fig. 3).

Rice. 3. Median 14 funds
Fashion
The term was first introduced by Pearson in 1894. Fashion is the number that occurs most often in the sample (the most fashionable). Fashion describes well, for example, the typical reaction of drivers to a traffic signal to stop traffic. A classic example of the use of fashion is the choice of the size of the produced batch of shoes or the color of the wallpaper. If a distribution has multiple modes, then it is said to be multimodal or multimodal (has two or more "peaks"). The multimodal distribution provides important information about the nature of the variable under study. For example, in sociological surveys, if a variable represents a preference or attitude towards something, then multimodality could mean that there are several distinctly different opinions. Multimodality also serves as an indicator that the sample is not homogeneous and the observations may be generated by two or more "overlapped" distributions. Unlike the arithmetic mean, outliers do not affect the mode. For continuously distributed random variables, such as the average annual returns of mutual funds, the mode sometimes does not exist at all (or does not make sense). Since these indicators can take on a variety of values, repeating values are extremely rare.
Quartiles
Quartiles are measures that are most commonly used to evaluate the distribution of data when describing the properties of large numerical samples. While the median splits the ordered array in half (50% of the array elements are less than the median and 50% are greater), quartiles break the ordered dataset into four parts. The Q 1 , median and Q 3 values are the 25th, 50th and 75th percentile, respectively. The first quartile Q 1 is a number that divides the sample into two parts: 25% of the elements are less than, and 75% are more than the first quartile.
The third quartile Q 3 is a number that also divides the sample into two parts: 75% of the elements are less than, and 25% are more than the third quartile.
To calculate quartiles in versions of Excel prior to 2007, the function =QUARTILE(array, part) was used. Starting with Excel 2010, two functions apply:
- =QUARTILE.ON(array, part)
- =QUARTILE.EXC(array, part)
These two functions give slightly different values (Figure 4). For example, when calculating the quartiles for a sample containing data on the average annual return of 15 very high-risk mutual funds, Q 1 = 1.8 or -0.7 for QUARTILE.INC and QUARTILE.EXC, respectively. By the way, the QUARTILE function used earlier corresponds to the modern QUARTILE.ON function. To calculate quartiles in Excel using the above formulas, the data array can be left unordered.

Rice. 4. Calculate quartiles in Excel
Let's emphasize again. Excel can calculate quartiles for univariate discrete series, containing the values of a random variable. The calculation of quartiles for a frequency-based distribution is given in the section below.
geometric mean
Unlike the arithmetic mean, the geometric mean measures how much a variable has changed over time. The geometric mean is the root n th degree from the product n values (in Excel, the function = CUGEOM is used):
G= (X 1 * X 2 * ... * X n) 1/n
A similar parameter - the geometric mean of the rate of return - is determined by the formula:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
where R i- rate of return i-th period of time.
For example, suppose the initial investment is $100,000. By the end of the first year, it drops to $50,000, and by the end of the second year, it recovers to the original $100,000. The rate of return on this investment over a two-year period is equal to 0, since the initial and final amount of funds are equal to each other. However, the arithmetic mean of annual rates of return is = (-0.5 + 1) / 2 = 0.25 or 25%, since the rate of return in the first year R 1 = (50,000 - 100,000) / 100,000 = -0.5 , and in the second R 2 = (100,000 - 50,000) / 50,000 = 1. At the same time, the geometric mean of the rate of return for two years is: G = [(1–0.5) * (1 + 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Thus, the geometric mean more accurately reflects the change (more precisely, the absence of change) in the volume of investments over the biennium than the arithmetic mean.
Interesting Facts. First, the geometric mean will always be less than the arithmetic mean of the same numbers. Except for the case when all the taken numbers are equal to each other. Secondly, having considered the properties of a right triangle, one can understand why the mean is called geometric. The height of a right-angled triangle, lowered to the hypotenuse, is the average proportional between the projections of the legs on the hypotenuse, and each leg is the average proportional between the hypotenuse and its projection on the hypotenuse (Fig. 5). This gives a geometric way of constructing the geometric mean of two (lengths) segments: you need to build a circle on the sum of these two segments as a diameter, then the height, restored from the point of their connection to the intersection with the circle, will give the desired value:

Rice. 5. The geometric nature of the geometric mean (figure from Wikipedia)
The second important property of numerical data is their variation characterizing the degree of dispersion of the data. Two different samples can differ both in mean values and in variations. However, as shown in fig. 6 and 7, two samples can have the same variation but different means, or the same mean and completely different variation. The data corresponding to polygon B in Fig. 7 change much less than the data from which polygon A was built.

Rice. 6. Two symmetric bell-shaped distributions with the same spread and different mean values

Rice. 7. Two symmetric bell-shaped distributions with the same mean values and different scatter
There are five estimates of data variation:
- span,
- interquartile range,
- dispersion,
- standard deviation,
- the coefficient of variation.
scope
The range is the difference between the largest and the smallest elements samples:
Swipe = XMax-XMin
The range of a sample containing data on the average annual returns of 15 very high-risk mutual funds can be calculated using an ordered array (see Figure 4): range = 18.5 - (-6.1) = 24.6. This means that the difference between the highest and lowest average annual returns for very high risk funds is 24.6%.
The range measures the overall spread of the data. Although the sample range is a very simple estimate of the total spread of the data, its weakness is that it does not take into account exactly how the data is distributed between the minimum and maximum elements. This effect is well seen in Fig. 8 which illustrates samples having the same range. The B scale shows that if the sample contains at least one extreme value, the sample range is a very inaccurate estimate of the spread of the data.

Rice. 8. Comparison of three samples with the same range; the triangle symbolizes the support of the balance, and its location corresponds to the average value of the sample
Interquartile range
The interquartile, or mean, range is the difference between the third and first quartiles of the sample:
Interquartile range \u003d Q 3 - Q 1
This value makes it possible to estimate the spread of 50% of the elements and not to take into account the influence of extreme elements. The interquartile range for a sample containing data on the average annual returns of 15 very high-risk mutual funds can be calculated using the data in Figure 2. 4 (for example, for the function QUARTILE.EXC): Interquartile range = 9.8 - (-0.7) = 10.5. The interval between 9.8 and -0.7 is often referred to as the middle half.
It should be noted that the Q 1 and Q 3 values, and hence the interquartile range, do not depend on the presence of outliers, since their calculation does not take into account any value that would be less than Q 1 or greater than Q 3 . The total quantitative characteristics, such as the median, the first and third quartiles, and the interquartile range, which are not affected by outliers, are called robust indicators.
While the range and interquartile range provide an estimate of the total and mean scatter of the sample, respectively, neither of these estimates takes into account exactly how the data are distributed. Variance and standard deviation free from this shortcoming. These indicators allow you to assess the degree of fluctuation of the data around the mean. Sample variance is an approximation of the arithmetic mean calculated from the squared differences between each sample element and the sample mean. For a sample of X 1 , X 2 , ... X n the sample variance (denoted by the symbol S 2 is given by the following formula:

In general, the sample variance is the sum of the squared differences between the sample elements and the sample mean, divided by a value equal to the sample size minus one:

where - arithmetic mean, n- sample size, X i - i-th sample element X. In Excel before version 2007, the function =VAR() was used to calculate the sample variance, since version 2010, the function =VAR.V() is used.
The most practical and widely accepted estimate of data scatter is standard deviation. This indicator is denoted by the symbol S and is equal to square root from the sample variance:

In Excel before version 2007, the =STDEV() function was used to calculate the standard deviation, from version 2010 the =STDEV.B() function is used. To calculate these functions, the data array can be unordered.
Neither the sample variance nor the sample standard deviation can be negative. The only situation in which the indicators S 2 and S can be zero is if all elements of the sample are equal. In this completely improbable case, the range and interquartile range are also zero.
Numeric data is inherently volatile. Any variable can take on many different values. For example, different mutual funds have different rates of return and loss. Due to the variability of numerical data, it is very important to study not only estimates of the mean, which are summative in nature, but also estimates of the variance, which characterize the scatter of the data.
The variance and standard deviation allow us to estimate the spread of data around the mean, in other words, to determine how many elements of the sample are less than the mean, and how many are greater. The dispersion has some valuable mathematical properties. However, its value is the square of a unit of measure - a square percentage, a square dollar, a square inch, etc. Therefore, a natural estimate of the variance is the standard deviation, which is expressed in the usual units of measurement - percent of income, dollars or inches.
The standard deviation allows you to estimate the amount of fluctuation of the sample elements around the mean value. In almost all situations, the majority of observed values lie within plus or minus one standard deviation from the mean. Therefore, knowing the arithmetic mean of the sample elements and the standard sample deviation, it is possible to determine the interval to which the bulk of the data belongs.
The standard deviation of returns on 15 very high-risk mutual funds is 6.6 (Figure 9). This means that the profitability of the bulk of funds differs from the average value by no more than 6.6% (i.e., it fluctuates in the range from – S= 6.2 – 6.6 = –0.4 to + S= 12.8). In fact, this interval contains a five-year average annual return of 53.3% (8 out of 15) of funds.

Rice. 9. Standard deviation
Note that in the process of summing the squared differences, items that are farther from the mean gain more weight than items that are closer. This property is the main reason why the arithmetic mean is most often used to estimate the mean of a distribution.
The coefficient of variation
Unlike previous scatter estimates, the coefficient of variation is a relative estimate. It is always measured as a percentage, not in the original data units. The coefficient of variation, denoted by the symbols CV, measures the scatter of the data around the mean. The coefficient of variation is equal to the standard deviation divided by the arithmetic mean and multiplied by 100%:

where S- standard sample deviation, - sample mean.
The coefficient of variation allows you to compare two samples, the elements of which are expressed in different units of measurement. For example, the manager of a mail delivery service intends to upgrade the fleet of trucks. When loading packages, there are two types of restrictions to consider: the weight (in pounds) and the volume (in cubic feet) of each package. Assume that in a sample of 200 bags, the average weight is 26.0 pounds, the standard deviation of the weight is 3.9 pounds, the average package volume is 8.8 cubic feet, and the standard deviation of the volume is 2.2 cubic feet. How to compare the spread of weight and volume of packages?
Since the units of weight and volume are different, the manager must compare the relative spread of these values. The weight variation coefficient is CV W = 3.9 / 26.0 * 100% = 15%, and the volume variation coefficient CV V = 2.2 / 8.8 * 100% = 25% . Thus, the relative scatter of packet volumes is much larger than the relative scatter of their weights.
Distribution form
The third important property of the sample is the form of its distribution. This distribution can be symmetrical or asymmetric. To describe the shape of a distribution, it is necessary to calculate its mean and median. If these two scores are the same, the variable is said to be symmetrically distributed. If the mean value of a variable is greater than the median, its distribution has a positive skewness (Fig. 10). If the median is greater than the mean, the distribution of the variable is negatively skewed. Positive skewness occurs when the mean increases to unusually high values. Negative skewness occurs when the mean decreases to unusually small values. A variable is symmetrically distributed if it does not take on any extreme values in either direction, such that large and small values of the variable cancel each other out.

Rice. 10. Three types of distributions
The data depicted on the A scale have a negative skewness. This figure shows a long tail and skew to the left, caused by the presence of unusually small values. These extremely small values shift the mean value to the left, and it becomes less than the median. The data shown on scale B are distributed symmetrically. The left and right halves of the distribution are their mirror images. Large and small values balance each other, and the mean and median are equal. The data shown on scale B has a positive skewness. This figure shows a long tail and skew to the right, caused by the presence of unusually high values. These too large values shift the mean to the right, and it becomes larger than the median.
In Excel, descriptive statistics can be obtained using the add-in Analysis package. Go through the menu Data → Data analysis, in the window that opens, select the line Descriptive statistics and click Ok. In the window Descriptive statistics be sure to indicate input interval(Fig. 11). If you want to see descriptive statistics on the same sheet as the original data, select the radio button output interval and specify the cell where you want to place the upper left corner of the displayed statistics (in our example, $C$1). If you want to output data to a new sheet or to a new workbook, simply select the appropriate radio button. Check the box next to Final statistics. Optionally, you can also choose Difficulty level,k-th smallest andk-th largest.
If on deposit Data in the area of Analysis you don't see the icon Data analysis, you must first install the add-on Analysis package(see, for example,).

Rice. 11. Descriptive statistics of the five-year average annual returns of funds with very high levels of risk, calculated using the add-on Data analysis Excel programs
Excel calculates a number of statistics discussed above: mean, median, mode, standard deviation, variance, range ( interval), minimum, maximum, and sample size ( check). In addition, Excel calculates some new statistics for us: standard error, kurtosis, and skewness. standard error equals the standard deviation divided by the square root of the sample size. asymmetry characterizes the deviation from the symmetry of the distribution and is a function that depends on the cube of differences between the elements of the sample and the mean value. Kurtosis is a measure of the relative concentration of data around the mean versus the tails of the distribution, and depends on the differences between the sample and the mean raised to the fourth power.
Calculation of descriptive statistics for the general population
The mean, scatter, and shape of the distribution discussed above are sample-based characteristics. However, if the dataset contains numerical measurements of the entire population, then its parameters can be calculated. These parameters include the mean, variance, and standard deviation of the population.
Expected value is equal to the sum of all values of the general population divided by the volume of the general population:

where µ - expected value, Xi- i-th variable observation X, N- the volume of the general population. In Excel, to calculate the mathematical expectation, the same function is used as for the arithmetic mean: =AVERAGE().
Population variance equal to the sum of the squared differences between the elements of the general population and mat. expectation divided by the size of the population:

where σ2 is the variance of the general population. Excel prior to version 2007 uses the =VAR() function to calculate the population variance, starting with version 2010 =VAR.G().
population standard deviation equals the square root of the population variance:

Prior to Excel 2007, the function =SDV() was used to calculate the population standard deviation, from version 2010 =SDV.Y(). Note that the formulas for population variance and standard deviation are different from the formulas for sample variance and standard deviation. When calculating sample statistics S2 and S the denominator of the fraction is n - 1, and when calculating the parameters σ2 and σ - the volume of the general population N.
rule of thumb
In most situations, a large proportion of observations are concentrated around the median, forming a cluster. In data sets with positive skewness, this cluster is located to the left (i.e., below) the mathematical expectation, and in sets with negative skewness, this cluster is located to the right (i.e., above) of the mathematical expectation. Symmetric data have the same mean and median, and the observations cluster around the mean, forming a bell-shaped distribution. If the distribution does not have a pronounced skewness, and the data is concentrated around a certain center of gravity, a rule of thumb can be used to estimate variability, which says: if the data has a bell-shaped distribution, then approximately 68% of the observations are within one standard deviation of the mathematical expectation, Approximately 95% of the observations are within two standard deviations of the expected value, and 99.7% of the observations are within three standard deviations of the expected value.
Thus, the standard deviation, which is an estimate of the average fluctuation around the mathematical expectation, helps to understand how the observations are distributed and to identify outliers. It follows from the rule of thumb that for bell-shaped distributions, only one value in twenty differs from the mathematical expectation by more than two standard deviations. Therefore, values outside the interval µ ± 2σ, can be considered outliers. In addition, only three out of 1000 observations differ from the mathematical expectation by more than three standard deviations. Thus, values outside the interval µ ± 3σ are almost always outliers. For distributions that are highly skewed or not bell-shaped, the Biename-Chebyshev rule of thumb can be applied.
More than a hundred years ago, the mathematicians Bienamay and Chebyshev independently discovered useful property standard deviation. They found that for any data set, regardless of the shape of the distribution, the percentage of observations that lie at a distance not exceeding k standard deviations from mathematical expectation, not less (1 – 1/ 2)*100%.
For example, if k= 2, the Biename-Chebyshev rule states that at least (1 - (1/2) 2) x 100% = 75% of the observations must lie in the interval µ ± 2σ. This rule is true for any k exceeding one. The Biename-Chebyshev rule is of a very general nature and is valid for distributions of any kind. It indicates the minimum number of observations, the distance from which to the mathematical expectation does not exceed a given value. However, if the distribution is bell-shaped, the rule of thumb more accurately estimates the concentration of data around the mean.
Computing descriptive statistics for a frequency-based distribution
If the original data is not available, the frequency distribution becomes the only source of information. In such situations, it is possible to calculate approximate values of quantitative indicators of the distribution, such as the arithmetic mean, standard deviation, quartiles.
If the sample data is presented as a frequency distribution, an approximate value of the arithmetic mean can be calculated, assuming that all values within each class are concentrated at the midpoint of the class:

where - sample mean, n- number of observations, or sample size, With- the number of classes in the frequency distribution, mj- middle point j-th class, fj- frequency corresponding to j-th class.
To calculate the standard deviation from the frequency distribution, it is also assumed that all values within each class are concentrated at the midpoint of the class.

To understand how the quartiles of the series are determined based on frequencies, let us consider the calculation of the lower quartile based on data for 2013 on the distribution of the Russian population by average per capita cash income (Fig. 12).

Rice. 12. The share of the population of Russia with per capita monetary income on average per month, rubles
To calculate the first quartile of the interval variation series, you can use the formula:

where Q1 is the value of the first quartile, xQ1 is the lower limit of the interval containing the first quartile (the interval is determined by the accumulated frequency, the first exceeding 25%); i is the value of the interval; Σf is the sum of the frequencies of the entire sample; probably always equal to 100%; SQ1–1 is the cumulative frequency of the interval preceding the interval containing the lower quartile; fQ1 is the frequency of the interval containing the lower quartile. The formula for the third quartile differs in that in all places, instead of Q1, you need to use Q3, and substitute ¾ instead of ¼.
In our example (Fig. 12), the lower quartile is in the range 7000.1 - 10,000, the cumulative frequency of which is 26.4%. The lower limit of this interval is 7000 rubles, the value of the interval is 3000 rubles, the accumulated frequency of the interval preceding the interval containing the lower quartile is 13.4%, the frequency of the interval containing the lower quartile is 13.0%. Thus: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13.4) / 13 \u003d 9677 rubles.
Pitfalls associated with descriptive statistics
In this note, we looked at how to describe a data set using various statistics that estimate its mean, scatter, and distribution. next step is the analysis and interpretation of data. So far, we have studied the objective properties of data, and now we turn to their subjective interpretation. Two mistakes lie in wait for the researcher: an incorrectly chosen subject of analysis and an incorrect interpretation of the results.
An analysis of the performance of 15 very high-risk mutual funds is quite unbiased. He led to completely objective conclusions: all mutual funds have different returns, the spread of fund returns ranges from -6.1 to 18.5, and the average return is 6.08. Objectivity of data analysis is ensured the right choice total quantitative indicators of distribution. Several methods for estimating the mean and scatter of data were considered, and their advantages and disadvantages were indicated. How to choose the right statistics that provide an objective and unbiased analysis? If the data distribution is slightly skewed, should the median be chosen over the arithmetic mean? Which indicator more accurately characterizes the spread of data: standard deviation or range? Should the positive skewness of the distribution be indicated?
On the other hand, data interpretation is a subjective process. Different people come to different conclusions, interpreting the same results. Everyone has their own point of view. Someone considers the total average annual returns of 15 funds with a very high level of risk to be good and is quite satisfied with the income received. Others may think that these funds have too low returns. Thus, subjectivity should be compensated by honesty, neutrality and clarity of conclusions.
Ethical Issues
Data analysis is inextricably linked to ethical issues. One should be critical of the information disseminated by newspapers, radio, television and the Internet. Over time, you will learn to be skeptical not only about the results, but also about the goals, subject and objectivity of research. The famous person said it best British politician Benjamin Disraeli: "There are three kinds of lies: lies, damned lies, and statistics."
As noted in the note, ethical issues arise when choosing the results that should be presented in the report. Both positive and negative results should be published. In addition, when making a report or written report, the results must be presented honestly, neutrally and objectively. Distinguish between bad and dishonest presentations. To do this, it is necessary to determine what the intentions of the speaker were. Sometimes the speaker omits important information out of ignorance, and sometimes deliberately (for example, if he uses the arithmetic mean to estimate the mean of clearly skewed data in order to get the desired result). It is also dishonest to suppress results that do not correspond to the point of view of the researcher.
Materials from the book Levin et al. Statistics for managers are used. - M.: Williams, 2004. - p. 178–209
QUARTILE function retained to align with earlier versions of Excel
Signs of units of statistical aggregates are different in their meaning, for example, the wages of workers of one profession of an enterprise are not the same for the same period of time, market prices for the same products are different, crop yields in the farms of the region, etc. Therefore, in order to determine the value of a feature characteristic of the entire population of units under study, average values are calculated.
average value –
it is a generalizing characteristic of the set of individual values of some quantitative trait.
The population studied by a quantitative attribute consists of individual values; they are influenced by both general causes and individual conditions. In the average value, the deviations characteristic of the individual values are canceled out. The average, being a function of a set of individual values, represents the entire set with one value and reflects the common thing that is inherent in all its units.
The average calculated for populations consisting of qualitatively homogeneous units is called typical average. For example, you can calculate the average monthly salary of an employee of one or another professional group (miner, doctor, librarian). Of course, the levels of monthly wages of miners, due to the difference in their qualifications, length of service, hours worked per month and many other factors, differ from each other, and from the level of average wages. However, the average level reflects the main factors that affect the level of wages, and mutually offset the differences that arise due to the individual characteristics of the employee. The average wage reflects the typical level of wages for this type of worker. Obtaining a typical average should be preceded by an analysis of how this population is qualitatively homogeneous. If the population consists of separate parts, it should be divided into typical groups (average temperature in the hospital).
Average values used as characteristics for heterogeneous populations are called system averages. For example, the average gross domestic product(GDP) per capita, the average value of consumption of various groups of goods per person and other similar values, representing the general characteristics of the state as a single economic system.
The average should be calculated for populations consisting of enough a large number units. Compliance with this condition is necessary for the law to come into force. big numbers, as a result of which random deviations of individual values from the general trend cancel each other out.
Types of averages and methods for calculating them
The choice of the type of average is determined by the economic content of a certain indicator and the initial data. However, any average value must be calculated so that when it replaces each variant of the averaged feature, the final, generalizing, or, as it is commonly called, does not change. defining indicator, which is related to the average. For example, when replacing the actual speeds on individual sections of the path, their average speed should not change the total distance traveled vehicle at the same time; when replacing the actual wages of individual employees of the enterprise with the average wage, the wage fund should not change. Consequently, in each specific case, depending on the nature of the available data, there is only one true average value of the indicator that is adequate to the properties and essence of the socio-economic phenomenon under study.
The most commonly used are the arithmetic mean, harmonic mean, geometric mean, mean square, and mean cubic.
The listed averages belong to the class power average and are combined by the general formula:
,
where is the average value of the studied trait;
m is the exponent of the mean;
– current value (variant) of the averaged feature;
n is the number of features.
Depending on the value of the exponent m, the following types of power averages are distinguished:
at m = -1 – mean harmonic ;
at m = 0 – geometric mean ;
at m = 1 – arithmetic mean;
at m = 2 – root mean square ;
at m = 3 - average cubic.
When using the same initial data, the larger the exponent m in the above formula, the larger the value of the average value:
.
This property of power-law means to increase with an increase in the exponent of the defining function is called the rule of majorance of means.
Each of the marked averages can take two forms: simple and weighted.
The simple form of the middle applies when the average is calculated on primary (ungrouped) data. weighted form– when calculating the average for secondary (grouped) data.
Arithmetic mean
The arithmetic mean is used when the volume of the population is the sum of all individual values of the varying attribute. It should be noted that if the type of average is not indicated, the arithmetic average is assumed. Its logical formula is: ![]()
simple arithmetic mean calculated by ungrouped data
according to the formula: ![]() or ,
or ,
where are the individual values of the attribute;
j is the serial number of the unit of observation, which is characterized by the value ;
N is the number of observation units (set size).
Example. In the lecture “Summary and grouping of statistical data”, the results of observing the work experience of a team of 10 people were considered. Calculate the average work experience of the workers of the brigade. 5, 3, 5, 4, 3, 4, 5, 4, 2, 4.
According to the formula of the arithmetic mean simple, one also calculates chronological averages, if the time intervals for which the characteristic values are presented are equal.
Example. The volume of products sold for the first quarter amounted to 47 den. units, for the second 54, for the third 65 and for the fourth 58 den. units The average quarterly turnover is (47+54+65+58)/4 = 56 den. units
If momentary indicators are given in the chronological series, then when calculating the average, they are replaced by half-sums of values at the beginning and end of the period.
If there are more than two moments and the intervals between them are equal, then the average is calculated using the formula for the average chronological
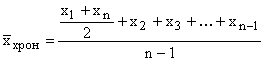 ,
,
where n is the number of time points
When the data is grouped by attribute values
(i.e., a discrete variational distribution series is constructed) with weighted arithmetic mean is calculated using either frequencies , or frequencies of observation of specific values of the feature , the number of which (k) is significantly less than number observations (N) .
,
,
where k is the number of groups of the variation series,
i is the number of the group of the variation series.
Since , and , we obtain the formulas used for practical calculations:
and
Example. Let's calculate the average length of service of the working teams for the grouped series.
a) using frequencies:
b) using frequencies:
When the data is grouped by intervals
, i.e. are presented in the form of interval distribution series; when calculating the arithmetic mean, the middle of the interval is taken as the value of the feature, based on the assumption of a uniform distribution of population units in this interval. The calculation is carried out according to the formulas:
and
where is the middle of the interval: ,
where and are the lower and upper boundaries of the intervals (provided that the upper boundary of this interval coincides with the lower boundary of the next interval).
Example. Let us calculate the arithmetic mean of the interval variation series constructed from the results of a study of the annual wages of 30 workers (see the lecture "Summary and grouping of statistical data").
Table 1 - Interval variation series of distribution.
Intervals, UAH |
Frequency, pers. |
frequency, |
The middle of the interval |
||
600-700 |
3 |
0,10 |
(600+700):2=650 |
1950 |
65 |
![]() UAH or
UAH or ![]() UAH
UAH
The arithmetic means calculated on the basis of the initial data and interval variation series may not coincide due to the uneven distribution of the attribute values within the intervals. In this case, for a more accurate calculation of the arithmetic weighted average, one should use not the middle of the intervals, but the arithmetic simple averages calculated for each group ( group averages). The average calculated from group means using a weighted calculation formula is called general average.
The arithmetic mean has a number of properties.
1. The sum of deviations of the variant from the mean is zero:
.
2. If all values of the option increase or decrease by the value A, then the average value increases or decreases by the same value A: ![]()
3. If each option is increased or decreased by B times, then the average value will also increase or decrease by the same number of times:
or ![]()
4. The sum of the products of the variant by the frequencies is equal to the product of the average value by the sum of the frequencies: ![]()
5. If all frequencies are divided or multiplied by any number, then the arithmetic mean will not change: 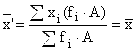
6) if in all intervals the frequencies are equal to each other, then the arithmetic weighted average is equal to the simple arithmetic average: ![]() ,
,
where k is the number of groups in the variation series.
Using the properties of the average allows you to simplify its calculation.
Suppose that all options (x) are first reduced by the same number A, and then reduced by a factor of B. The greatest simplification is achieved when the value of the middle of the interval with the highest frequency is chosen as A, and the value of the interval as B (for rows with the same intervals). The quantity A is called the origin, so this method of calculating the average is called way b ohm reference from conditional zero or way of moments.
After such a transformation, we obtain a new variational distribution series, the variants of which are equal to . Their arithmetic mean, called moment of the first order, is expressed by the formula and according to the second and third properties, the arithmetic mean is equal to the mean of the original version, reduced first by A, and then by B times, i.e. .
For getting real average(middle of the original row) you need to multiply the moment of the first order by B and add A: 
The calculation of the arithmetic mean by the method of moments is illustrated by the data in Table. 2.
Table 2 - Distribution of employees of the enterprise shop by length of service
Work experience, years |
Amount of workers |
Interval midpoint |
|||
0 – 5 |
12 |
2,5 |
15 |
3 |
36 |
Finding the moment of the first order ![]() . Then, knowing that A = 17.5, and B = 5, we calculate the average work experience of the shop workers:
. Then, knowing that A = 17.5, and B = 5, we calculate the average work experience of the shop workers:
years
Average harmonic
As shown above, the arithmetic mean is used to calculate the average value of a feature in cases where its variants x and their frequencies f are known.
If the statistical information does not contain frequencies f for individual options x of the population, but is presented as their product , the formula is applied average harmonic weighted. To calculate the average, denote , whence . Substituting these expressions into the weighted arithmetic mean formula, we obtain the weighted harmonic mean formula:  ,
,
where is the volume (weight) of the indicator attribute values in the interval with number i (i=1,2, …, k).
Thus, the harmonic mean is used in cases where it is not the options themselves that are subject to summation, but their reciprocals: ![]() .
.
In cases where the weight of each option is equal to one, i.e. individual values of the inverse feature occur once, apply simple harmonic mean: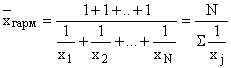 ,
,
where are individual variants of the inverse trait that occur once;
N is the number of options.
If there are harmonic averages for two parts of the population with a number of and, then the total average for the entire population is calculated by the formula: 
and called weighted harmonic mean of the group means.
Example. Three deals were made during the first hour of trading on the currency exchange. Data on the amount of hryvnia sales and the hryvnia exchange rate against the US dollar are given in Table. 3 (columns 2 and 3). Determine the average exchange rate of the hryvnia against the US dollar for the first hour of trading.
Table 3 - Data on the course of trading on the currency exchange
The average dollar exchange rate is determined by the ratio of the amount of hryvnias sold in the course of all transactions to the amount of dollars acquired as a result of the same transactions. The total amount of the hryvnia sale is known from column 2 of the table, and the amount of dollars purchased in each transaction is determined by dividing the hryvnia sale amount by its exchange rate (column 4). A total of $22 million was purchased during three transactions. This means that the average hryvnia exchange rate for one dollar was  .
.
The resulting value is real, because his substitution of the actual hryvnia exchange rates in transactions will not change the total amount of sales of the hryvnia, which acts as defining indicator: mln. UAH
If the arithmetic mean was used for the calculation, i.e. ![]() hryvnia, then at the exchange rate for the purchase of 22 million dollars. UAH 110.66 million would have to be spent, which is not true.
hryvnia, then at the exchange rate for the purchase of 22 million dollars. UAH 110.66 million would have to be spent, which is not true.
Geometric mean
The geometric mean is used to analyze the dynamics of phenomena and allows you to determine the average growth rate. When calculating the geometric mean, the individual values of the attribute are relative indicators of dynamics, built in the form of chain values, as the ratio of each level to the previous one.
The geometric simple mean is calculated by the formula: 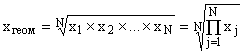 ,
,
where is the sign of the product,
N is the number of averaged values.
Example. The number of registered crimes over 4 years increased by 1.57 times, including for the 1st - by 1.08 times, for the 2nd - by 1.1 times, for the 3rd - by 1.18 and for the 4th - 1.12 times. Then the average annual growth rate of the number of crimes is: , i.e. The number of registered crimes has grown by an average of 12% annually.
1,8
-0,8
0,2
1,0
1,4
1
3
4
1
1
3,24
0,64
0,04
1
1,96
3,24
1,92
0,16
1
1,96
To calculate the mean square weighted, we determine and enter in the table and. Then the average value of deviations of the length of products from a given norm is equal to: 
The arithmetic mean in this case would be unsuitable, because as a result, we would get zero deviation.
The use of the root mean square will be discussed later in the exponents of variation.